
Written by: Ali-Reza Adl-Tabatabai, Founder and CEO, Gitar
Key Takeaways
- Self-hosted AI code review with Ollama keeps all code on your own infrastructure and avoids SaaS fees of $15–30 per developer each month.
- Top 2026 models like Qwen3-Coder-Next (65% HumanEval, 8GB RAM) and DeepSeek V3.2 Speciale (90% LiveCodeBench) now deliver production-grade reviews through simple Ollama commands.
- Teams can adopt three practical setups: git-lrc integration, GitHub Actions workflows, and custom Flask/Docker deployments using copy-paste configurations.
- Security hardening remains essential: bind Ollama to localhost, restrict access with firewall rules, and upgrade to Ollama 0.7.0+ to reduce exposed server and GGUF parsing risks.
- DIY Ollama focuses on suggestions and manual fixes, while Gitar’s 14-day Team Plan trial adds validated auto-fixes that repair broken builds for you.
Why Self-Hosted AI Code Review with Ollama in 2026 Matters
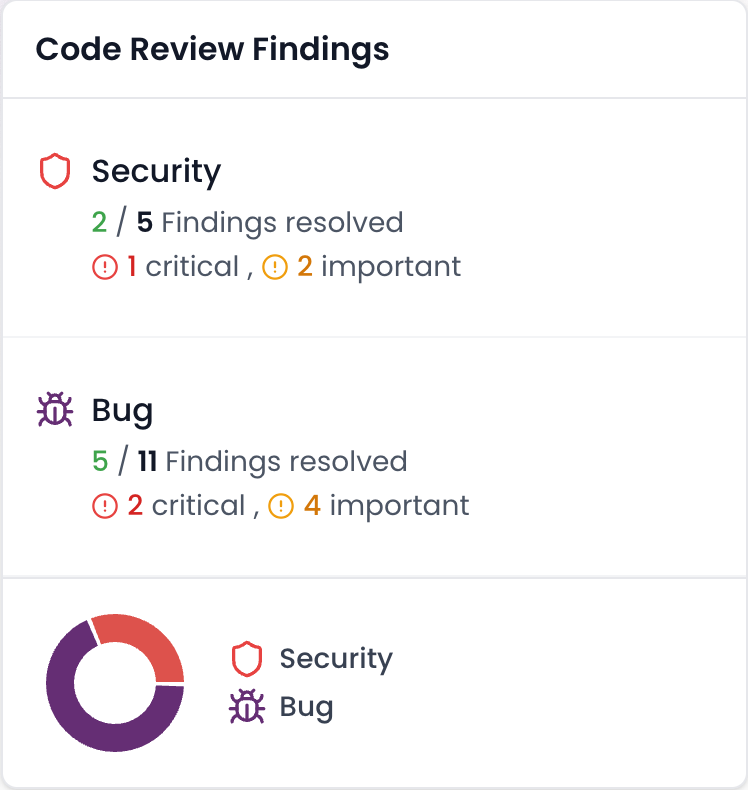
Self hosted ai code review with ollama gives engineering teams three concrete benefits: strict data privacy, predictable infrastructure-only costs, and full control over which models run in production. The landscape has evolved significantly with Qwen3-Coder-Next achieving 65% on HumanEval and DeepSeek V3.2 Speciale reaching 90% on LiveCodeBench. DIY setups still trap teams in manual fix application, scaling overhead, and security exposure, while Gitar’s auto-fixing platform validates and applies changes directly inside your CI pipeline. See the Gitar documentation for a deeper look at this platform architecture.
The following comparison highlights how SaaS tools, DIY Ollama, and Gitar differ on privacy, cost, and automation for production deployments:
|
Feature |
SaaS Tools |
Ollama DIY |
Gitar |
|
Privacy |
Code sent externally |
Fully local |
Enterprise Plan: Agent runs in your CI |
|
Cost |
$15-30/dev/month |
Infrastructure only |
Try Gitar Team Plan free for 14 days |
|
Auto-fix |
Suggestions only |
Manual implementation |
CI-validated fixes |
Best Ollama Models for Code Review in 2026
The top-performing ollama models for code review have dramatically improved in 2026. As mentioned in the key takeaways, Qwen3-Coder-Next leads the field through its efficient MoE architecture, while DeepSeek V3.2 Speciale offers even higher benchmark performance for teams with enterprise hardware. The table below shows how these models balance accuracy against RAM requirements so you can match them to your infrastructure.
|
Model |
HumanEval Score |
RAM Required |
Ollama Command |
|
Qwen3-Coder-Next |
65% |
8GB |
ollama run qwen3-coder-next |
|
Llama 3.3 70B |
88% |
32GB+ |
ollama run llama3.3:70b |
|
DeepSeek R1 14B |
92% |
16GB |
ollama run deepseek-r1:14b |
|
GPT-OSS 20B |
82% |
16GB |
ollama run gpt-oss:20b |
Use this JSON prompt template to test review quality consistently across models:
3 Proven Setup Methods for Ollama Code Review
Method 1: git-lrc / LiveReview for Local Workflows
Use git-lrc to add self hosted ollama code review directly into your local git workflow with minimal configuration.
Method 2: Ollama Code Review GitHub Action
Create .github/workflows/ollama-review.yml to run ai code review github checks on every pull request using your self-hosted runners.
Method 3: Custom Flask Integration with Docker Compose
Run a dedicated reviewer service with Docker Compose so your CI, GitHub, or GitLab webhooks can call Ollama through a simple HTTP API.
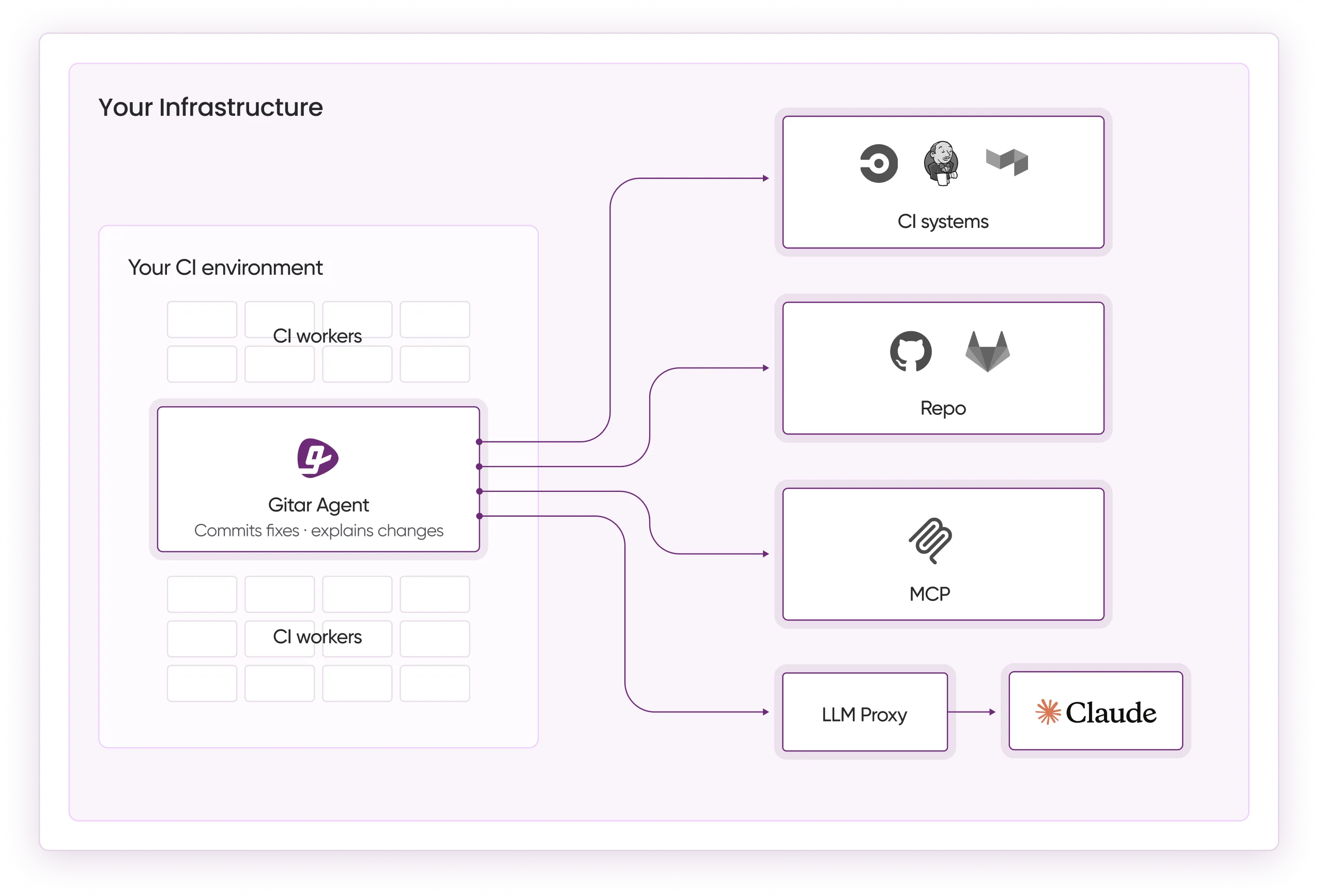
Once your Flask service runs in production, you will face two common parsing challenges. Large diffs need splitting into chunks under 4000 tokens, and webhook handlers must use async processing for files over 100KB to avoid timeouts.
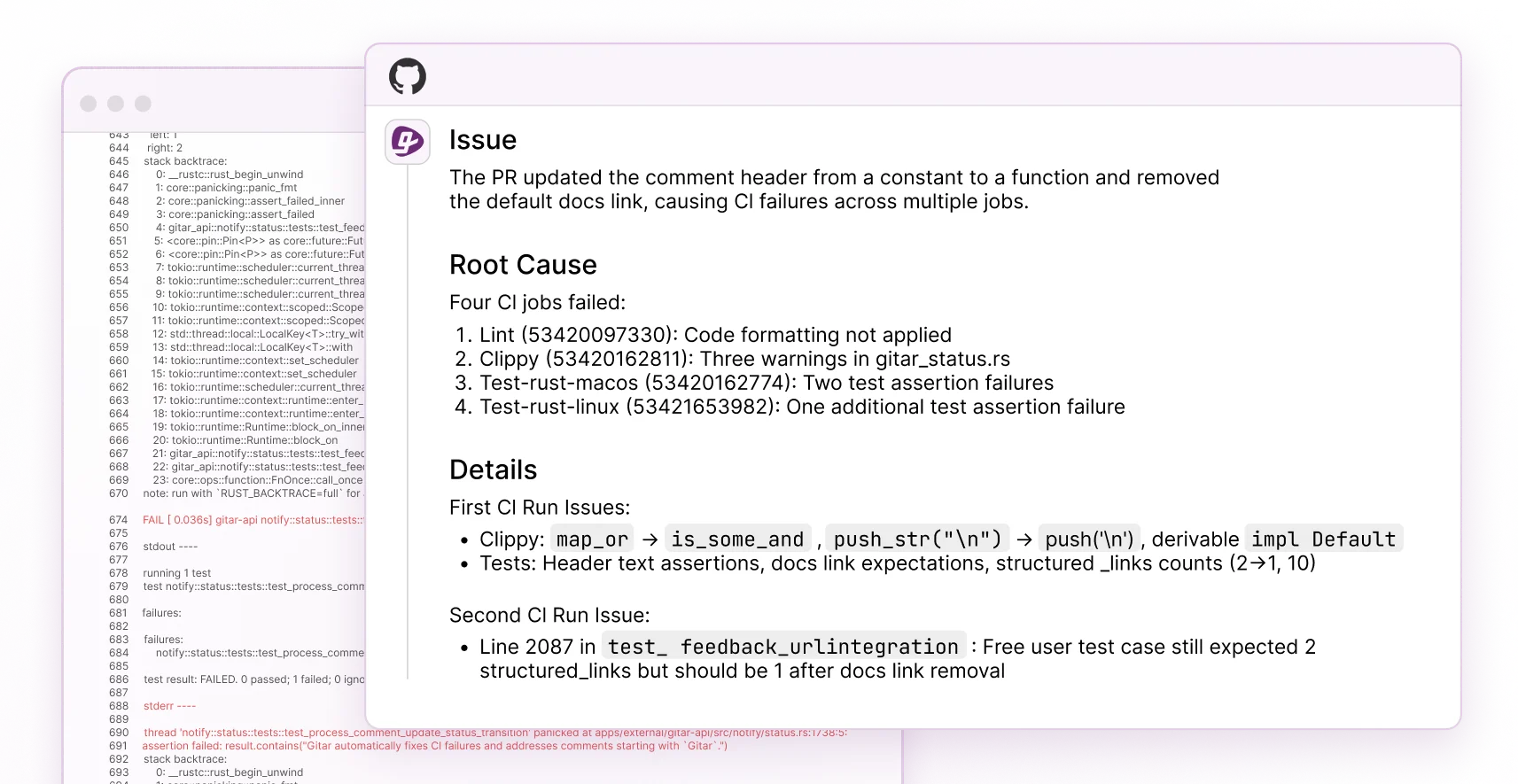
Security Hardening and Scaling for Ollama
Securing self-hosted Ollama instances starts with reducing exposure similar to the 175,000 publicly exposed servers identified in January 2026. Bind Ollama to localhost using OLLAMA_HOST=127.0.0.1 and restrict port 11434 to trusted IP ranges through firewall rules.
These network controls block direct external access but do not address flaws inside the Ollama binary. Update to Ollama 0.7.0+ immediately to patch critical Out-Of-Bounds Write vulnerabilities in GGUF parsing that could allow code execution even on firewalled hosts. For VS Code integration, install the Ollama extension, point it at your secured endpoint, and pair it with FAISS-based RAG to keep reviews accurate across large monorepos.
DIY Ollama Limits Compared to Gitar’s Auto-Fix Platform
Self hosted ai code review with ollama delivers privacy and cost control but still demands manual effort to apply fixes and wire CI workflows. Unlike the manual implementation required with DIY Ollama, Gitar’s platform described earlier guarantees green builds by validating fixes before they land in your main branch. The Gitar docs provide step-by-step guides for connecting this platform to your existing CI pipeline.
The table below highlights the most important capability gaps for teams deciding between DIY and a managed healing platform:
|
Capability |
Ollama DIY |
Gitar |
|
Auto-apply fixes |
Manual implementation |
CI-validated automation |
|
CI healing |
No integration |
Automatic failure resolution |
|
Team scaling |
Infrastructure management |
Managed platform |
|
ROI calculation |
1hr/day lost per dev |
$750K annual savings |
For a 20-developer team, DIY solutions can reach roughly $1M annually in lost productivity from repeated manual fix cycles. Gitar’s healing engine converts those cycles into measurable velocity gains. Experience this difference with the Gitar Team Plan and skip the heavy lifting of building auto-fix logic yourself.
Quickstart: Self-Hosted Ollama Review in 10 Minutes
- Install Docker: curl -fsSL https://get.docker.com | sh
- Run Ollama: docker run -d -p 11434:11434 –name ollama ollama/ollama
- Pull model: docker exec ollama ollama pull qwen3-coder-next
- Configure a webhook endpoint for GitHub or GitLab events.
- Set up repository integration to send diffs to your Ollama endpoint.
- Test with a sample pull request and review the generated feedback.
- Monitor results and iterate on prompts to match your team’s standards.
Implementation Phases and Common Pitfalls
Phase 1 focuses on prototype deployment with basic model testing so you can confirm that reviews add value. Once you validate that the model produces useful feedback, Phase 2 introduces security hardening and team-wide rollout to move from proof-of-concept into production. Teams that rush through Phase 1 often hit the “suggestion trap,” RAG configuration failures that hurt context, and memory issues that Gitar’s architecture avoids through hierarchical context retention at line, pull request, repository, and organization levels.
Performance constraints appear in both accuracy and latency. Complex refactoring accuracy sits near 65% for local models compared to 88% for cloud options, so teams must weigh privacy against capability gaps. Shared Ollama servers also add 10–30ms of network latency, which approaches cloud response times while still requiring you to maintain the underlying infrastructure.
FAQ
What is the best Ollama model for code review in 2026?
Qwen3-Coder-Next leads with 65% HumanEval performance and efficient 8GB RAM usage, which suits most self-hosted deployments. Teams with stronger hardware can consider DeepSeek V3.2 Speciale at 90% LiveCodeBench, although it demands significantly more compute.
How do I integrate Ollama with VS Code for code review?
Install the Ollama VS Code extension and point it to your local instance at http://localhost:11434. Enable code review features in the extension settings and choose your preferred model for analysis.
Can I use Ollama for GitHub Actions workflows?
Yes, you can, but you need self-hosted runners because GitHub-hosted runners cannot reach localhost Ollama services. Each workflow run must download models again, which can add up to 30 minutes of setup time for larger models.
What are the security risks of self-hosted Ollama?
Major risks include public exposure of the API on port 11434, vulnerabilities in versions before 0.7.0, and the absence of built-in authentication. Always bind to localhost, keep versions updated, and enforce strict firewall rules.
How does self-hosted Ollama compare to Gitar?
Self-hosted Ollama delivers privacy and zero recurring license costs but still requires manual fix application, infrastructure management, and custom CI wiring. Gitar focuses on automatic fix application, CI healing, and a managed platform experience while maintaining enterprise-grade security.
Self hosted ai code review with ollama works well for teams that prioritize data sovereignty and accept manual overhead. The combination of privacy benefits and scaling challenges still caps overall velocity gains. See how Gitar’s healing platform compares by starting your trial and experience automatic CI failure resolution with validated fixes applied directly to your codebase.