
Written by: Ali-Reza Adl-Tabatabai, Founder and CEO, Gitar
Key Takeaways
- Free AI code review tools average 60-70% accuracy. They detect syntax reliably at 80-90% but miss many logic errors at 40-55% and generate 15-35% false positives.
- Benchmarks across 50+ PRs in Python, JS, and Go for 2026 show CodeRabbit leading free tiers at 85% syntax accuracy, although it still offers no auto-fix support.
- Gitar’s healing engine validates fixes against CI systems and commits only passing changes, which keeps builds green instead of adding more suggestions.
- High false positive rates, often 20-30% from tools like Copilot and Cursor, slow developers and flood inboxes with distracting notifications.
- Teams that adopt validation-focused AI review reduce PR merge time from 24 hours to 90 minutes. See how CI-validated auto-fixes perform in your codebase during a 14-day Team Plan trial.
How We Tested Free AI Code Review Tools
Our 2026 evaluation measured free AI code review tools against more than 50 pull requests from public repositories. Each PR contained intentionally injected bugs across three categories: syntax errors such as missing semicolons and typos, security vulnerabilities such as SQL injection and XSS, and logic errors such as incorrect algorithms and edge case handling. We scored each tool on detection percentage, false positive rate, and auto-fix accuracy, then validated fixes through CI pipeline execution to confirm that builds passed.
Testing sources included direct tool trials, DEV.to community benchmarks, and Reddit developer feedback to keep results grounded in real-world usage. The sample focused on common programming languages such as Python, JavaScript, and Go, which reflect what most teams run in production. Teams that want to replicate or extend this testing approach can review implementation details in the Gitar documentation.
Top 7 Free AI Code Review Tools Overview
Seven tools emerged as leaders in the free AI code review space. Gitar offers comprehensive auto-fixes with CI integration through its full-featured 14-day trial. CodeRabbit provides PR summaries and suggestions on its free tier. Sourcery focuses on Python refactoring recommendations. GitHub Copilot includes IDE-integrated review capabilities. Cursor offers reasoning-based code analysis. Greptile’s free tier provides codebase context analysis. ChatGPT and Claude enable prompt-based, do-it-yourself reviews.
To see how a healing engine behaves on your own repositories, try Gitar’s 14-day Team Plan trial and compare it directly with suggestion-only tools.
Free AI Code Review Accuracy Rates 2026
The following table compares accuracy rates for six permanently free-tier tools. Gitar’s metrics are excluded because its 14-day trial exposes full Team Plan capabilities rather than a restricted free tier, which makes direct comparison with always-free options misleading.
|
Tool |
Syntax % |
Security % |
Logic % |
False Pos % |
|
CodeRabbit |
85 |
61 |
55 |
15 |
|
Sourcery |
88 |
70 |
50 |
20 |
|
GitHub Copilot |
82 |
<50 |
52 |
25 |
|
Cursor |
80 |
68 |
48 |
22 |
|
Greptile free |
78 |
65 |
45 |
30 |
|
ChatGPT/Claude |
70 |
60 |
40 |
35 |
The table reveals a consistent pattern across free tools. Syntax detection remains strong between 70% and 88%, while logic error detection rarely exceeds 55%. False positives range from 15% to 35%, which creates significant noise for developers who must manually sift through incorrect alerts.
Gitar’s competitive edge comes from its healing engine, which validates fixes against CI systems before committing and keeps builds green instead of relying on hopeful suggestions. First-generation AI review tools recorded 48% false positive rates, while modern tools such as CodeRabbit now reach roughly 15%.
False Positives and Developer Pain Points
Reddit developers consistently report that 20-30% false positive noise slows their work and breaks concentration. Notification spam from scattered inline comments forces frequent context switching and interrupts deep focus. The overall false positive range spans 15-35%, yet many teams feel the impact most acutely in that 20-30% band where every review feels cluttered.
Gitar reduces this friction through single dashboard comments that update in place and consolidate all findings into one interface. CI analysis, review feedback, and rule evaluations appear together, which keeps noise lower and makes each review easier to process.
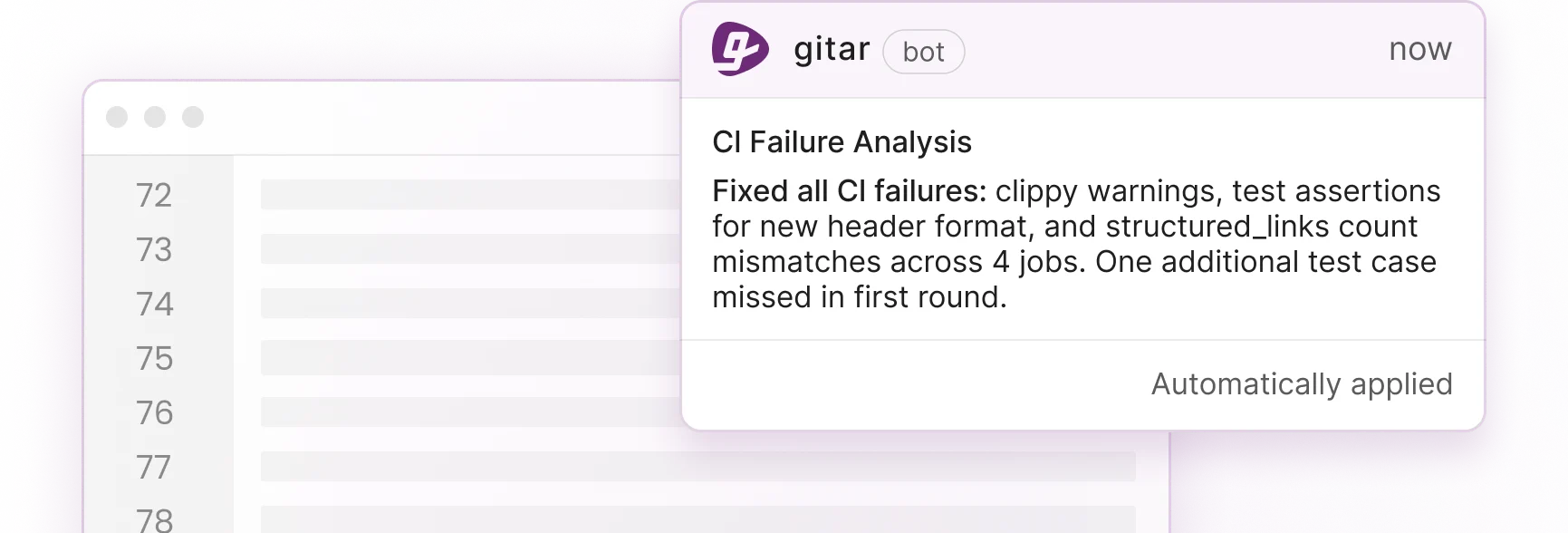
Gitar’s Healing Engine for CI-Validated Fixes
Gitar’s healing engine analyzes CI failures, generates candidate fixes, validates those fixes in your CI pipeline, and then commits only working solutions. This validation-first architecture creates a fundamentally different experience than suggestion-only tools that leave testing and verification to developers. Because every fix passes through CI before merge, Gitar can guarantee green builds instead of adding more manual review work.
The 30-second installation grants immediate access to a 14-day Team Plan trial. During this period, teams can use full auto-fix capabilities, CI integration across GitHub Actions, GitLab CI, CircleCI, and Buildkite, and workflow integrations with Jira and Slack. Experience the difference between suggestions and validated fixes during your trial and measure the impact on your own pipelines.
CodeRabbit Free Tier Breakdown
CodeRabbit ranks as successful across 51% of 309 PRs when scored with LLM-as-a-judge benchmarks. The free tier provides PR summaries and inline suggestions with GitHub integration, which helps teams catch many syntax issues. Benchmarks show 85% syntax detection and roughly 61% security detection.
CodeRabbit still lacks auto-fix capabilities and awareness of CI context, so developers must manually apply and validate every suggestion. With a 15% false positive rate, teams gain useful coverage but continue to spend time filtering out incorrect alerts and running follow-up checks.
Sourcery and GitHub Copilot Reviews
Sourcery specializes in Python refactoring suggestions with GitHub and GitLab PR integration and one-click accepts. It reaches 88% syntax detection but struggles with logic errors at 50% accuracy, which limits its ability to catch deeper defects. GitHub Copilot’s IDE-integrated reviews provide surface-level diff analysis with 82% syntax detection and under 50% security detection based on vulnerability benchmarks, along with 25% false positives.
AI-generated code contains 75% more logic and correctness issues, which increases the risk when teams rely on suggestion-only tools. This pattern underscores the need for validation mechanisms that confirm fixes in CI, a capability Gitar provides among free options through its trial.
Key Considerations and Gaps in Free AI Code Review
Developers prioritize low noise and validated fixes, while engineering leaders focus on clear ROI metrics. This dual requirement creates a challenge for tools that only suggest changes without proving that they work. The 90-minute median merge time mentioned earlier illustrates how advanced AI review can accelerate delivery when validation closes the loop.
For a 20-developer team, that improvement translates into meaningful savings. Productivity gains can reach $1M annually when teams remove manual CI failure resolution and shorten feedback loops. Gitar’s healing engine addresses both logic error detection and false positive reduction through CI validation, which delivers the faster velocity developers want and the measurable ROI leadership expects.
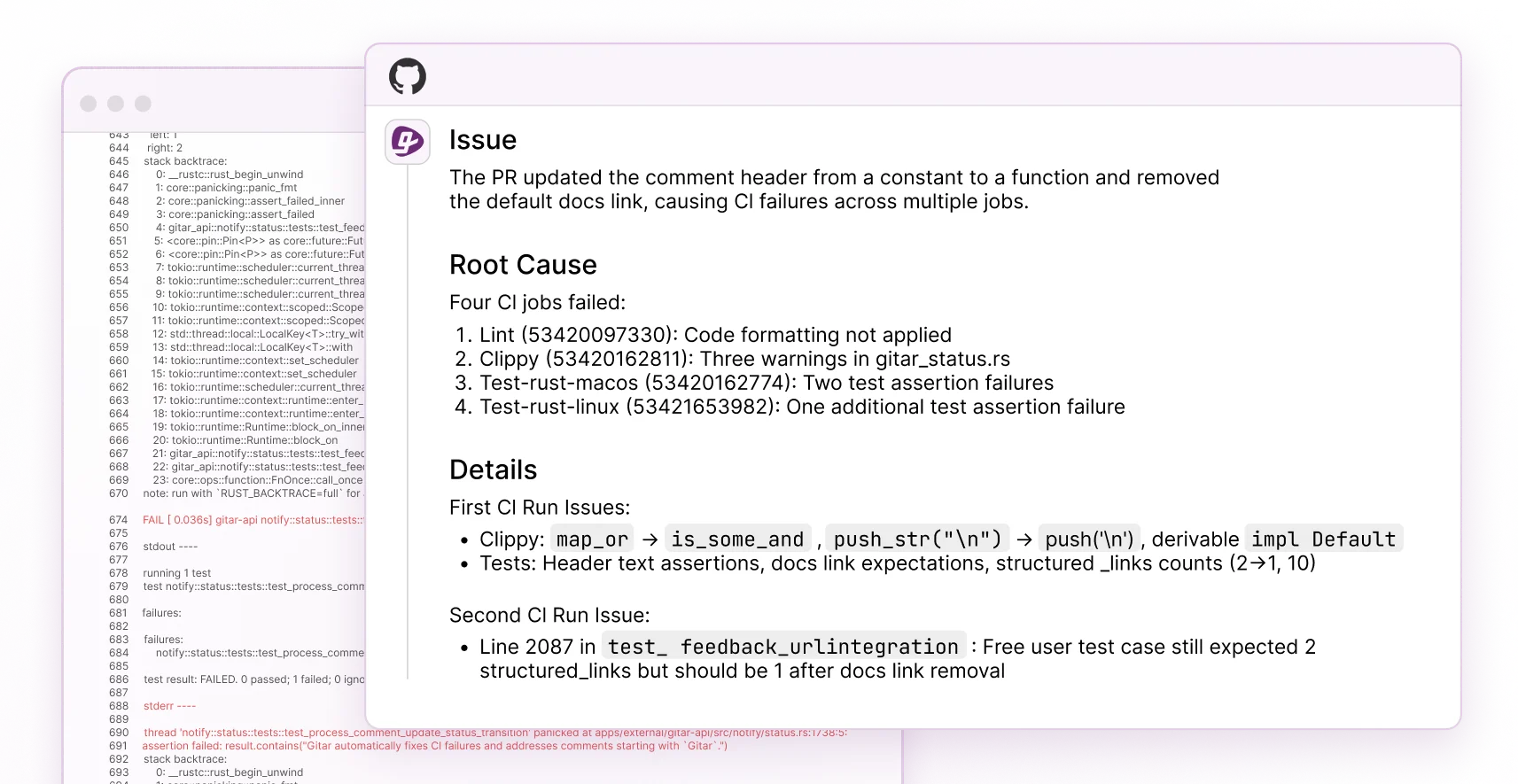
Test Gitar’s ROI impact with a 14-day Team Plan trial and track merge time, failure rates, and developer satisfaction before and after rollout.
Frequently Asked Questions
Which free AI code review tool has the best accuracy?
Gitar leads free AI code review options through its healing engine, which validates fixes against CI systems and commits only working solutions. This approach reduces false positives and produces reliable outcomes instead of unverified suggestions that may still fail.
How do free tools compare to paid AI code review options?
Most paid tools charge $15-30 per developer and still focus on suggestion-only features. Gitar’s 14-day Team Plan trial provides full auto-fix capabilities, CI integration, and validation mechanisms that exceed what many paid alternatives deliver. The trial supports unlimited repositories and users so teams can evaluate impact across their entire codebase before making a commitment.
Can free AI tools handle logic bugs and false positives effectively?
Traditional free tools struggle with logic errors, reaching only 40-55% detection rates and generating high false positive levels. Gitar’s CI validation system targets logic errors that break builds, then verifies fixes before committing them. This process reduces false positives and delivers dependable auto-fixes instead of speculative changes.
What integrations do free AI code review tools support?
Most free tools offer basic GitHub integration for pull request comments and suggestions. Gitar extends beyond this baseline with CI integration across GitHub Actions, GitLab CI, CircleCI, and Buildkite, along with workflow integrations for Jira and Slack. The platform supports both GitHub and GitLab repositories and allows natural language rule configuration for custom policies.
How can I test AI code review accuracy on my repositories?
Gitar’s 14-day Team Plan trial enables testing on your actual repositories with full auto-fix capabilities active. This setup provides real-world accuracy measurement on your codebase, team patterns, and CI configuration instead of relying only on synthetic benchmarks.
Conclusion and Next Steps for Your Team
Free AI code review tools average about 65% accuracy and often introduce significant false positive noise. Gitar delivers higher practical performance by pairing AI-generated fixes with CI validation through its healing engine, which keeps builds green and reduces manual rework. The comparison data and tool breakdowns in this guide give a starting point, but real value emerges when you test these approaches on your own repositories.
Teams facing persistent PR review bottlenecks now face a clear decision. They can continue using suggestion engines that require manual validation, or they can adopt a healing engine that commits only verified fixes. Get started with Gitar’s healing engine to automatically repair broken builds, shorten merge times, and evaluate the impact during your 14-day Team Plan trial.