
Key Takeaways
- Flaky tests create unreliable CI pipelines, slow releases, and significant hidden cost from reruns, investigation time, and context switching.
- AI-driven analysis and automated remediation can identify root causes in CI logs and apply validated fixes, reducing manual debugging work.
- Improved waits, retries, and test isolation reduce flakiness at the source, while monitoring and trend analysis keep test suites healthy over time.
- Developer-in-the-loop AI workflows help teams adopt automation safely, with clear explanations, approvals, and rollback options.
- Teams can use Gitar to automatically fix broken builds and move toward self-healing CI in 2026.
How Flaky Tests Drain Team Productivity and Budget
Flaky tests frequently pass and fail without code changes, which creates uncertainty about actual product quality. Flaky tests show inconsistent results for the same code, so teams spend time validating whether a failure is real or not.
The financial impact grows quickly. Repeated reruns, queued builds, and extra investigation time slow CI/CD pipelines and reduce productivity. For a 20-developer team, one hour lost per person per day can approach $1M per year in loaded cost. Shared databases, files, or ports and order-dependent tests increase this risk.
Teams can limit this waste by adopting tools that detect failures automatically and apply safe fixes with minimal human intervention. Gitar helps teams move from manual firefighting to automated resolution of CI failures.
1. Use AI Root Cause Analysis to Fix Flaky Tests Automatically
Manual debugging often means scanning logs, recreating environments, and iterating on speculative fixes. AI-powered analysis shortens this process by examining CI logs across runs, matching patterns, and mapping them to likely failure causes. Timing problems, race conditions, fragile selectors, and asynchronous UI behavior are all common sources that AI can detect consistently.
Gitar acts as a healing engine rather than a suggestion tool. The system analyzes CI failure logs, including test failures, identifies the root cause, and generates a candidate fix. It then validates that fix inside a replica of your CI environment, accounting for SDK versions, dependencies, and security scans, before committing it back.
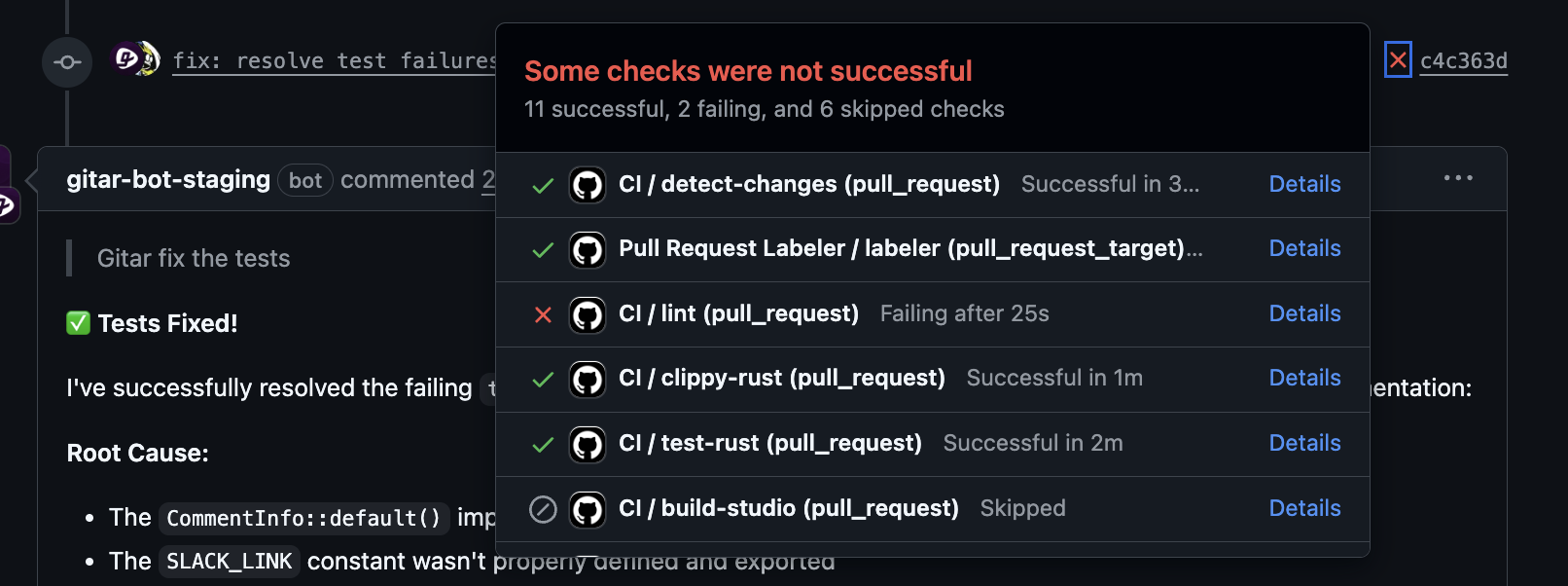
Teams can integrate this type of agent through GitHub Actions, GitLab CI, or similar platforms. The agent watches for failures, runs root cause analysis, and either opens a suggested patch or commits directly. Gitar supports different autonomy levels, so organizations can start with suggestions and move toward auto-commits with rollback as confidence grows.
2. Reduce Timing-Based Flakiness with Smarter Waits and Retries
Many flaky tests come from fixed timing assumptions that do not match real environments. Rigid timeouts, slow external services, and variable infrastructure all contribute to intermittent failures. Conditional waits such as “wait until element is visible” or “wait until request completes” provide more stable behavior than fixed sleep calls.
Carefully designed retries can filter out transient conditions without hiding true defects. Re-running tests and analyzing historical execution data helps distinguish systematic failures from environmental noise and informs retry policies.
Teams benefit from frameworks that support explicit waits and configurable retries, such as Selenium WebDriver with WebDriverWait or Cypress with built-in retry behavior for commands. CI pipelines can then apply limited retries at the test or job level, using metrics to confirm that retries reduce noise rather than mask defects. Adjusting timing assumptions and validating external dependencies remains essential when flakiness appears.
3. Improve Test Isolation and Environment Management
Strong test isolation reduces cross-test interference and makes failures more reproducible. Weak test data setup, shared mutable state, and saturated network or I/O resources all increase flakiness, especially in parallel runs.
Gitar mirrors full enterprise CI environments when generating fixes. It recreates details such as SDK combinations, build graphs, and security checks. This context ensures that proposed fixes work in the same conditions where failures occur. Issues like leftover browser drivers or polluted VM images can then be addressed through targeted cleanup and image management.
Teams can improve isolation by:
- Running tests in containers or ephemeral environments for consistent setup.
- Creating unique, per-test or per-run datasets and cleaning them afterward.
- Mocking or virtualizing external services to remove network dependency.
- Automating environment cleanup to avoid debris that affects later runs.
4. Monitor Test Health and Flakiness Trends Over Time
Continuous monitoring turns test stability into a measurable signal instead of an occasional surprise. Reviewing execution history and traces reveals patterns that one failing run may hide.
Useful metrics include:
- Pass and fail rates for each test over time.
- Average and p95 test duration trends.
- Recurring failure messages and stack traces.
- Correlation between failures, code changes, and deployments.
Tests that pass locally but fail in CI, or that pass after a rerun with no code changes, often indicate flakiness. Dashboards in tools like TestRail, or custom views on top of Prometheus and Grafana, can highlight unstable tests and guide refactoring work before they affect release schedules.
5. Use Developer-in-the-Loop AI for Safer Automation
Developer oversight helps teams adopt autonomous fixing with confidence. AI systems that provide clear diffs, explanations, and simple approval flows let developers keep control while reducing repetitive work.
Gitar supports this workflow through a configurable trust model. The system can open pull requests or comments with proposed fixes, describe the root cause and changes, and wait for human approval. Teams who gain confidence in the quality of fixes can shift to automatic application with rollback options.
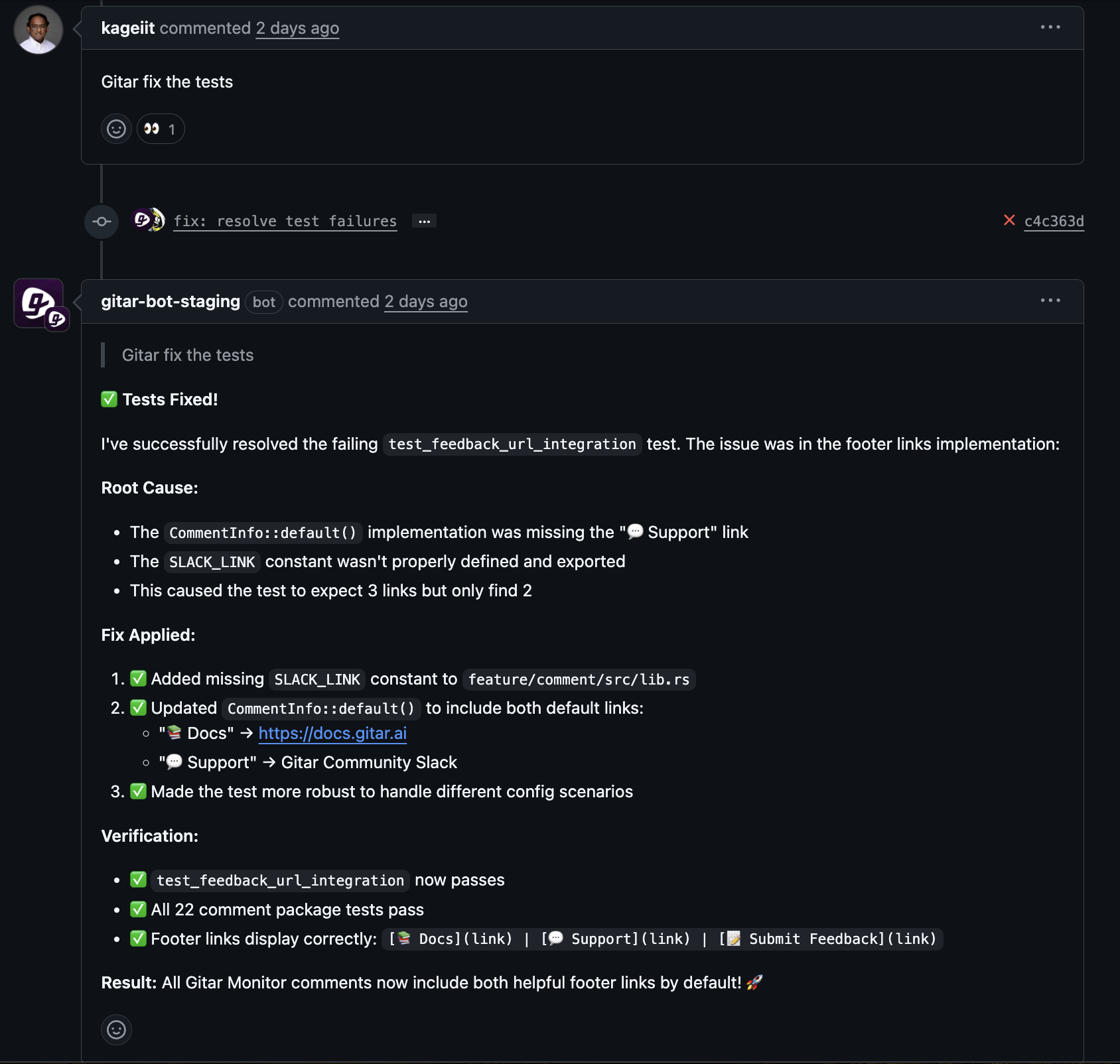
Teams can integrate AI feedback into existing code review systems through GitHub PR comments or similar tools. Clear explanations, low-friction approvals, and visible safety mechanisms increase trust and keep developers focused on higher-level design and feature work. Gitar provides this type of workflow within common CI and code hosting platforms.
Comparing Tools to Fix Flaky Tests Automatically
|
Tool Category |
Autonomous Fixes |
Environment Replication |
CI Platform Support |
|
Gitar (Healing Engine) |
Yes, applies and validates |
Full enterprise environments |
Cross-platform (GitHub, GitLab, CircleCI, BuildKite) |
|
AI Code Reviewers |
Varies, often suggestions only |
Varies by tool |
Multiple platforms supported |
|
Manual Debugging |
No autonomous fixes |
Depends on local setup |
Compatible with CI workflows |
The standout capability in this comparison is Gitar’s ability to both propose and implement fixes, then validate them inside a replicated CI environment. Other tools often stop at suggestions, which still require manual investigation and coding effort. Teams that want automatic, validated resolution of CI failures can adopt Gitar as a healing layer on top of existing pipelines.
Frequently Asked Questions About Automatically Fixing Flaky Tests
What kinds of flaky test issues can automated tools address?
Automated tools work best on flakiness caused by timing problems, race conditions, unstable external dependencies, and inconsistent environments. They can analyze logs and history to spot issues with fixed timeouts, shared test data, network timeouts, and concurrency defects that appear only under specific load or order.
How does a healing engine like Gitar differ from AI that only suggests changes?
A healing engine analyzes CI failures, generates a fix, applies it, and then re-runs the relevant parts of the pipeline to confirm success. Suggestion-only tools stop after describing the issue or generating a patch, so developers still need to validate and integrate the change. Gitar focuses on end-to-end resolution, including validation in your own CI environment.
Can automated tools work in complex enterprise CI setups?
Tools built for enterprise use, including Gitar, replicate the CI environment closely. They handle multiple SDK versions, layered dependencies, and security or quality scans such as SonarQube and Snyk, which ensures that fixes respect existing policies and workflows.
How can teams maintain trust while adopting autonomous fixing?
Teams can begin with conservative settings where the tool only suggests fixes in pull requests. After tracking accuracy and impact, they can enable automatic application for well-understood classes of failures, with audit logs and rollback options. This staged approach preserves trust while still capturing significant time savings.
What ROI can teams expect from automated CI failure fixing?
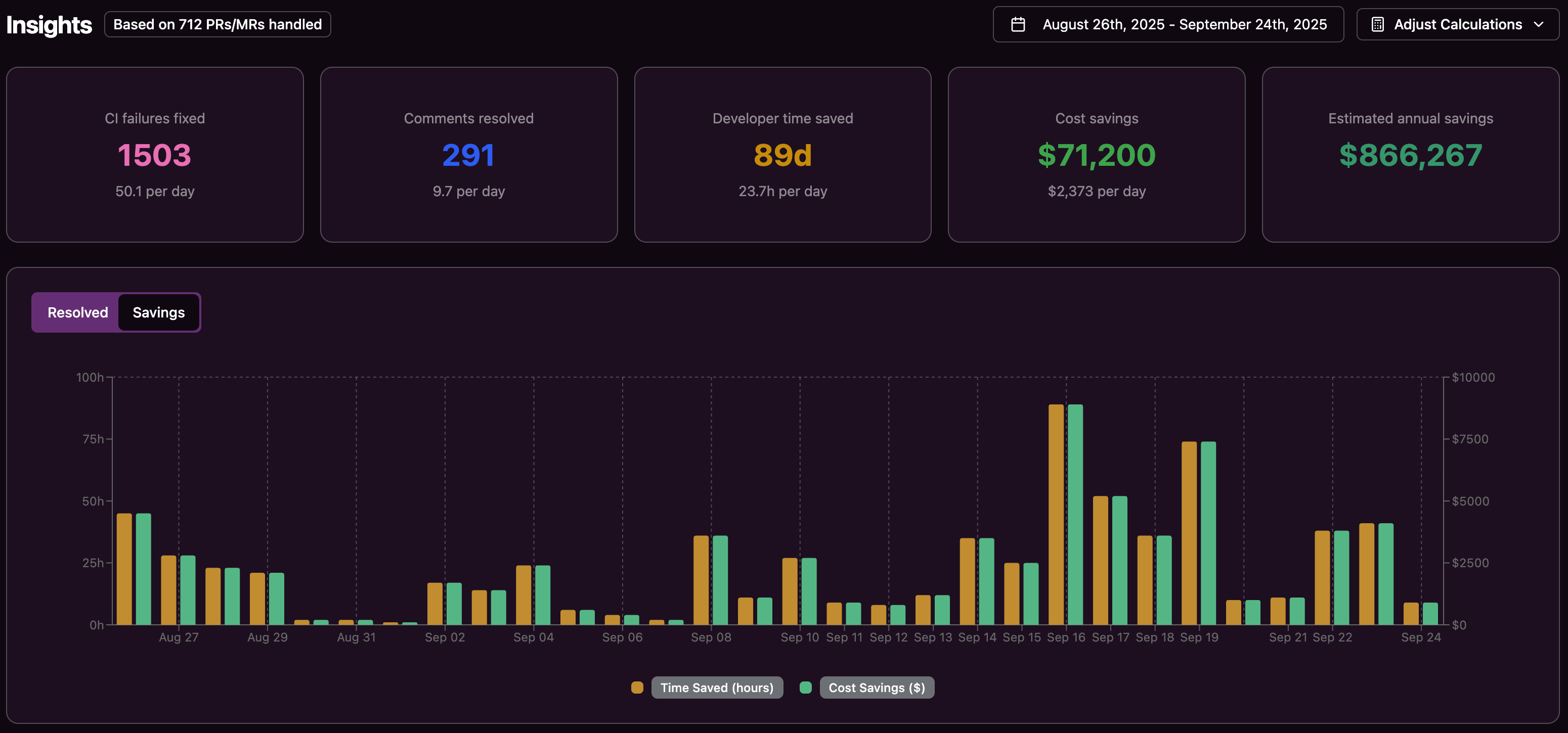
A 20-developer team that spends about an hour per person per day on CI investigation and reruns can lose around $1M per year in productivity. Cutting even half of that time with autonomous fixing can save hundreds of thousands of dollars annually, while also reducing frustration and improving delivery speed.
Conclusion: Move Toward Autonomous CI Failure Resolution in 2026
Flaky tests and other CI failures reduce release confidence, slow delivery, and increase engineering cost. Addressing them with AI-based analysis, better waits and retries, stronger isolation, and ongoing monitoring helps stabilize pipelines and reduce rework.
Teams that add a healing engine such as Gitar on top of these practices can automatically fix many CI failures, including flaky tests, and validate those fixes inside their own environments. This approach frees developers from repetitive debugging and supports more predictable, efficient delivery in 2026. Install Gitar to start automatically fixing broken builds and move closer to self-healing CI.