
Written by: Ali-Reza Adl-Tabatabai, Founder and CEO, Gitar
Key Takeaways
- Offline AI code generators like Ollama and GPT4All keep code on your machine, which suits air-gapped environments and strict data policies.
- Ollama stands out for simple setup, GPU auto-detection, and VS Code integration using Llama 3.2 at 58.9% HumanEval accuracy.
- GPT4All runs smoothly on CPU-only systems with a GUI and no GPU needs, which works well for laptops with 8GB RAM.
- AI-generated code often introduces more logic issues and longer PR reviews, so teams face a post-generation slowdown.
- Pair offline generators with Gitar’s automated code healing to keep CI green and ship production-ready code faster.
How To Benchmark Offline AI Code Generators in 2026
2026 benchmarks evaluate models across M1 Mac, RTX 3060, and CPU-only systems to reflect real developer hardware. For each setup, measure speed in tokens per second, HumanEval accuracy, IDE compatibility, installation complexity, and privacy guarantees. Combine data from LocalAimaster Research Team benchmarks with hands-on testing to confirm local-only operation with no data transmission.
Top 7 Offline AI Code Generators Developers Actually Use
1. Ollama for VS Code Workflows with Llama 3.2 – Updated April 2026
Ollama offers straightforward installation on macOS, Linux, and Windows and detects NVIDIA, AMD ROCm, and Apple Silicon GPUs for acceleration. The platform supports Llama 3.2, Mistral, and CodeLlama models and connects cleanly to VS Code through the Continue.dev extension.
|
Pros |
Cons |
Best For |
|
Simple install, GPU auto-detection, 70+ models |
Large model downloads, manual server start on Linux |
General development, VS Code users |
Installation: 1. macOS: Download from ollama.com or run brew install ollama. 2. Linux: curl -fsSL https://ollama.com/install.sh | sh then ollama serve. 3. Windows: Download the installer from ollama.com. 4. Pull a model with ollama pull llama3.2 which requires about 2GB.
Benchmark: Llama 3.2 reaches up to 213 tokens per second on an RTX 5090 while matching the accuracy mentioned earlier.
2. GPT4All for CPU-Only Laptops – Updated April 2026
GPT4All earns strong privacy ratings with zero analytics, no account requirement, and a LocalDocs feature for offline document analysis. It remains popular among r/LocalLLaMA’s 546,000 members because it runs entirely on CPUs.
|
Pros |
Cons |
Best For |
|
No GPU needed, GUI interface, document chat |
Slower than GPU tools, smaller model catalog |
CPU-only systems, document analysis |
Installation: 1. Download the desktop app from gpt4all.io. 2. Install the package for your operating system. 3. Use the interface to download recommended models. 4. Skip the command line entirely if you prefer.
Benchmark: Runs reliably on 8GB RAM with CPU-only inference at roughly 2 to 5 tokens per second.
3. Codeium for Air-Gapped Enterprise Teams – Updated April 2026
Codeium focuses on enterprises that need offline coding assistance in tightly controlled networks. Its on-premise deployment keeps all code inside your infrastructure while still providing autocomplete and chat across major IDEs.
|
Pros |
Cons |
Best For |
|
On-premise deployment, broad IDE coverage, team features |
Enterprise pricing, higher memory needs |
Large teams, air-gapped corporate environments |
Installation: 1. Deploy the Codeium server in your data center or private cloud. 2. Connect IDE plugins to the internal endpoint. 3. Configure authentication and team policies. 4. Roll out models to development teams.
Benchmark: Enterprise users report sub-second suggestions and 35 to 40 percent autocomplete acceptance in production projects.
4. Llama.cpp for Low-Resource Power Users – Updated April 2026
llama.cpp delivers efficient single-stream inference and powers tools like Ollama and LM Studio. It suits developers who want fine-grained control or need to squeeze performance from limited hardware.
|
Pros |
Cons |
Best For |
|
High single-stream efficiency, low resource usage, highly configurable |
Command-line focused, more technical setup |
Advanced users, constrained hardware |
Installation: 1. Clone from GitHub with git clone https://github.com/ggerganov/llama.cpp. 2. Compile using make. 3. Download GGUF models. 4. Run with ./main -m model.gguf -p “prompt”.
Benchmark: Optimized quantized models deliver strong performance when you run a single or small number of concurrent sessions.
5. LocalGPT and PrivateGPT for Document-Aware Coding – Updated April 2026
LocalGPT and PrivateGPT focus on document-aware code generation so you can query codebases, documentation, and project files while staying offline. These tools help the model understand project context, which improves suggestion relevance.
|
Pros |
Cons |
Best For |
|
Document ingestion, codebase awareness, long-context handling |
More complex setup, higher memory usage |
Large repositories, heavy documentation work |
Installation: 1. Clone the repository from GitHub. 2. Install Python dependencies. 3. Ingest documents or code. 4. Configure a local LLM backend.
Benchmark: Provides context-aware responses with typical memory needs between 8GB and 16GB RAM for document processing.
6. Tabnine Offline for IDE-First Teams – Updated April 2026
Tabnine Enterprise supports fully on-premise, air-gapped deployments that comply with SOC 2 Type II, GDPR, HIPAA, and PCI-DSS. Local models keep all code on the developer machine, which suits regulated industries.
|
Pros |
Cons |
Best For |
|
Enterprise compliance, learns team patterns, supports major IDEs |
Limited trial features, smaller offline models |
Regulated sectors, teams seeking consistent style |
Installation: 1. Install the Tabnine plugin in your IDE. 2. Switch configuration to local mode. 3. Download offline models. 4. Set team coding standards and policies.
Benchmark: LocalAimaster benchmarks show a 38 to 42 percent autocomplete acceptance rate.
7. PolyCoder and CodeT5 for Research and Niche Languages – Updated April 2026
PolyCoder and CodeT5 target research scenarios and language-specific workloads with models trained heavily on code repositories. They demand more technical setup but can perform well for certain languages and patterns.
|
Pros |
Cons |
Best For |
|
Code-focused training, strong research benchmarks, customizable |
Complex setup, limited ecosystem, experimental status |
Research projects, niche or legacy languages |
Installation: 1. Prepare a Python environment. 2. Install Hugging Face Transformers. 3. Download model weights. 4. Configure an inference pipeline.
Benchmark: Performance varies by language and model size, so teams often run their own targeted tests.
Offline AI Code Generation Comparison 2026
The following comparison highlights tradeoffs between speed, accuracy, IDE support, and hardware needs so you can match tools to your setup.
|
Tool |
Speed (CPU/GPU) |
HumanEval Score |
IDE Support |
Hardware Min |
|
Ollama |
5/213 t/s |
58.9% |
VS Code, JetBrains |
8GB RAM |
|
GPT4All |
2–5 t/s |
45% |
Standalone GUI |
8GB RAM |
|
Codeium |
Sub-second |
35–40% accept |
All major IDEs |
32GB RAM (Enterprise) |
|
llama.cpp |
10–30% faster |
Variable |
Command line |
4GB RAM |
Local models reach 42 to 65 percent on HumanEval yet still trail cloud models by 10 to 30 percent on complex benchmarks. While these tools handle private code generation well, they still leave you with code that often needs fixes before production.
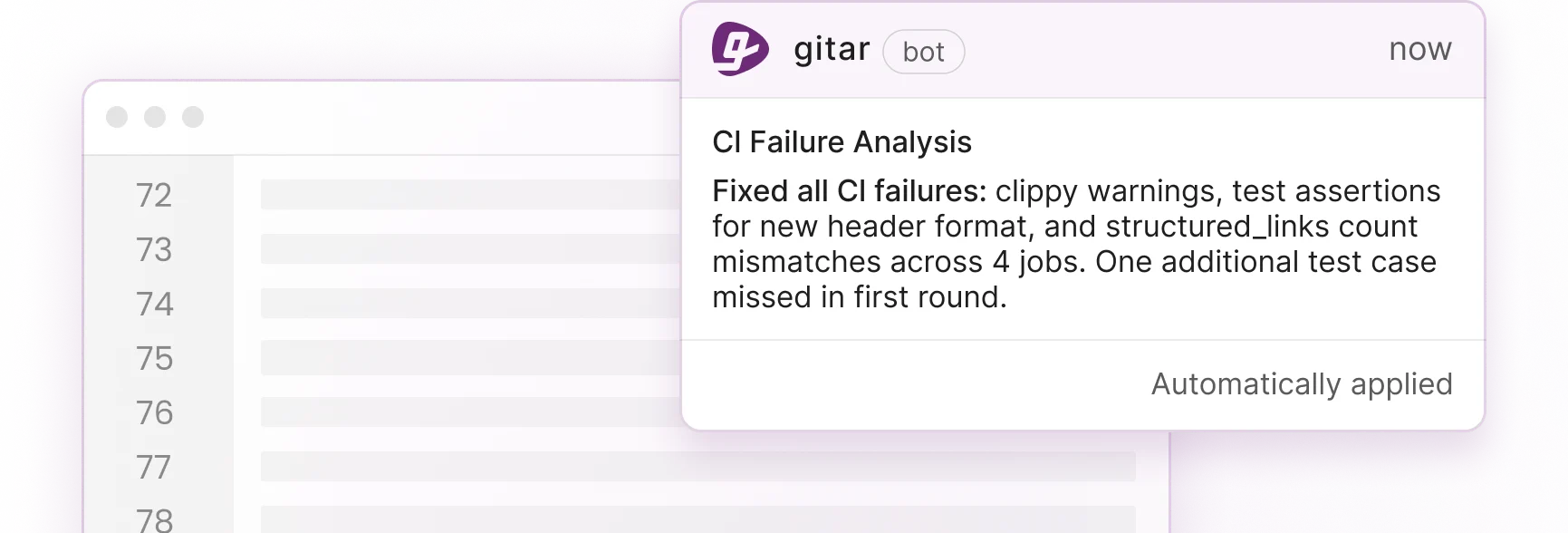
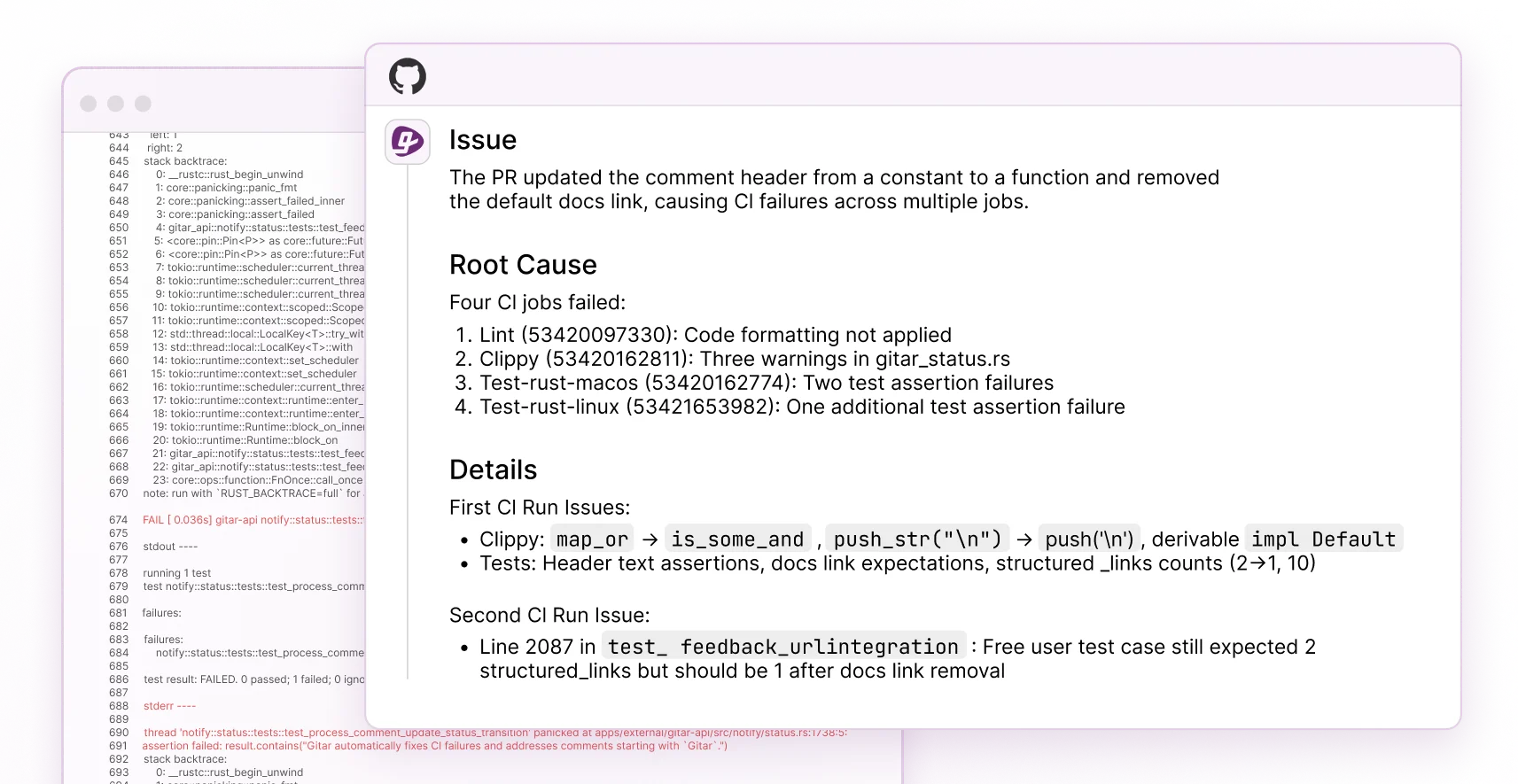
The Post-Generation Bottleneck with Offline AI & How Gitar Helps
Offline AI generation protects privacy but often increases rework because AI pull requests contain more logic issues and duplication. Internal data shows higher logic error rates and up to four times more duplicated code in AI-generated PRs. Traditional code review tools such as CodeRabbit, which costs about $15 to $30 per developer, only suggest changes and leave humans to implement them. Gitar’s healing engine analyzes CI failures, generates validated fixes, and commits working solutions directly to your repository.
The following comparison shows how automation from Gitar differs from suggestion-only tools.
|
Capability |
CodeRabbit/Greptile |
Gitar |
|
Auto-fix CI failures |
No |
Yes |
|
Validate fixes work |
No |
Yes |
|
Guarantee green builds |
No |
Yes |
Teams save about 45 minutes per developer each day by skipping manual fix implementation. While competitors charge premium prices for suggestions, Gitar offers a 14-day trial that demonstrates return on investment through real automation. Start your trial and connect it to your offline-generated code for a complete path to production.
Frequently Asked Questions
Best Offline AI Code Generator for VS Code
Ollama with the Continue.dev extension delivers strong VS Code integration for offline coding. The setup supports more than 70 models, including Llama 3.2 and CodeLlama, and provides autocomplete plus chat while keeping data local. Installation remains straightforward on all major platforms and includes automatic GPU detection.
Best Offline AI Code Generator for CPU-Only Systems
GPT4All suits CPU-only hardware and runs comfortably on 8GB RAM without a GPU. It offers a simple GUI, supports document analysis through LocalDocs, and maintains 2 to 5 tokens per second generation speed. The tool also avoids analytics and account requirements, which strengthens privacy.
Offline AI Code Generators vs GitHub Copilot for Privacy
Offline generators keep code entirely on your machine, while Copilot sends snippets to Microsoft servers for processing. Local tools help teams meet HIPAA, ITAR, CMMC, and defense regulations, which makes them a better fit for air-gapped environments, government work, and strict enterprise policies.
Minimum Hardware for Offline AI Coding
Most offline AI code generators need at least 8GB RAM, while 16GB improves performance for larger models. Storage requirements range from about 2GB for Llama 3.2 to roughly 40GB for Llama 3.1 70B. GPU acceleration speeds up generation but remains optional for lighter models such as GPT4All and smaller Ollama variants.
Integrating Gitar with Offline AI Code Generation
Gitar connects to your GitHub or GitLab repositories and watches for CI failures and review feedback. When tests or lint checks fail, Gitar analyzes the failure, proposes fixes, and commits working code after validation. This creates a continuous path from offline generation to production-ready code with minimal manual intervention.
Conclusion: Pair Offline Generation with Automated Fixing
Ollama currently leads for general development with strong VS Code integration, and GPT4All remains a solid choice for CPU-only setups. These tools solve private code generation, yet the largest productivity gains appear when you combine them with automated fixing and review. Run your preferred offline generator alongside Gitar to cover both creation and healing. Start your 14-day Gitar Team Plan trial.