Key Takeaways
- Reactive, manual incident response in DevOps inflates MTTR and forces constant context switching that reduces developer productivity.
- Clear monitoring, alerting, and workflow integration shorten detection and response times by putting incident data where engineers already work.
- Autonomous AI agents can handle common CI failures and review feedback, turning many incidents into routine, automated tasks.
- A self-healing culture, supported by automation and consistent post-incident learning, improves reliability and morale over time.
- Teams can use Gitar to automatically fix CI failures and review feedback within pull requests, reducing MTTR and freeing engineers to focus on core work. Install Gitar to automate fixes for broken builds.
The Cost of Reactive DevOps Incident Response
Manual incident response slows delivery and raises costs. When pipelines fail or code review feedback arrives, developers stop current work, open logs, and debug under time pressure. This pattern can consume a significant share of engineering time and makes every interruption more expensive than the fix itself.
Elite teams restore service within one hour on average, while low performers can take several days, which makes MTTR a clear performance signal. For a 20-developer team losing just one hour per day to CI and review issues, annual productivity loss can approach seven figures in loaded costs.
Distributed teams feel this even more. A pull request opened in one time zone and reviewed in another often experiences delays of a full day for each small round of feedback. Basic fixes stretch across multiple cycles, and suggestion-only AI tools still depend on developers to implement and validate every change.
Introducing Gitar: An Autonomous AI Agent for Self-Healing CI/CD
Gitar focuses on a narrow, high-impact problem: fixing CI failures and resolving code review feedback automatically. Instead of suggesting edits that engineers must apply, Gitar acts as an autonomous agent that changes code, re-runs checks, and updates pull requests.
Key capabilities include:
- Autonomous CI fixes that handle lint errors, test failures, and build issues by generating and applying code changes.
- In-PR code review assistance that addresses review feedback directly on pull requests and merge requests, reducing time zone delays.
- Environment replication that mirrors enterprise CI workflows, including dependencies and third-party tools, so fixes match real conditions.
- A configurable trust model that supports both suggestion-only workflows and automatic commits as confidence grows.
- Support for major platforms, including GitHub Actions, GitLab CI, CircleCI, BuildKite, and others.
Install Gitar to automate fixes for broken builds directly in your existing CI/CD setup.

1. Optimize Monitoring and Alerting for Faster Mean Time to Detection (MTTD)
Efficient automated response starts with clear visibility. Monitoring and observability tools should collect logs, metrics, and traces in one place so engineers can see how services behave and where failures begin.
Effective setups focus on:
- Reducing alert noise so only actionable issues reach on-call teams.
- Using anomaly detection and trend analysis to catch problems early.
- Sending targeted alerts through channels like Slack or PagerDuty with enough context to start triage immediately.
Good observability practices can reduce MTTR by roughly 50–70% by giving engineers a richer troubleshooting context. When alerts fire on CI failures, Gitar becomes the next link in the chain by taking that context and applying a fix automatically, turning detection into resolution with little or no manual work.
2. Use Autonomous AI Agents for First-Response Remediation
Autonomous agents handle the incidents that happen most often. Many CI/CD failures follow repeatable patterns, such as lint violations, flaky tests, snapshot updates, and straightforward dependency conflicts. These patterns make strong candidates for automated remediation.
A practical rollout often includes:
- Listing frequent CI failures and grouping them by pattern.
- Defining safe, repeatable remediation steps for each pattern.
- Allowing an agent to apply these fixes, then refining behavior from real outcomes.
Gitar receives CI failure notifications, inspects logs, determines an appropriate fix, applies the change, and commits it back to the branch. Many issues are resolved before the original author returns to the pull request.
Combining AIOps with automation frameworks has helped some organizations reduce downtime by around 60% and shorten MTTR for critical workloads. Autonomous CI remediation is a direct way to realize similar gains inside development workflows.
Add Gitar as your first-response agent for CI failures and reduce manual triage.
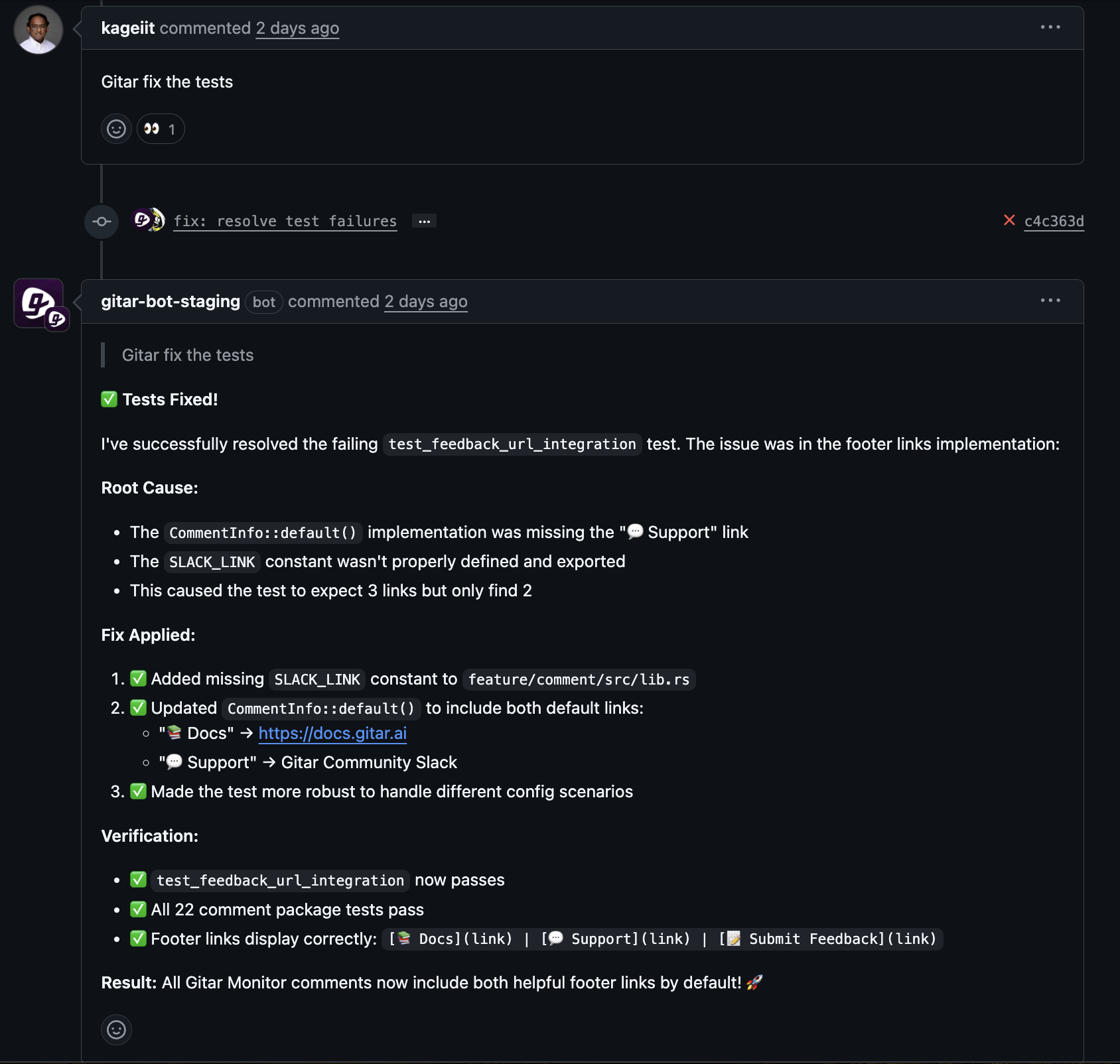
3. Embed Incident Response in Your CI/CD Workflow
Incident response works best when it lives where code lives. CI/CD systems already know which commits failed, which tests broke, and which pull requests are blocked, so they provide a natural surface for both detection and resolution.
Teams can improve flow by:
- Linking logs and traces directly from failed jobs to pull requests.
- Creating tickets automatically for failures that need human review.
- Allowing automation to post updates and outcomes on the pull request itself.
Gitar connects to GitHub, GitLab, and common CI platforms to post comments, fixes, and status updates right on PRs and MRs. Pull requests become the central place to see what failed, what changed, and whether the pipeline now passes.
Faster delivery cycles correlate with lower change failure rates and better MTTR when supported by automation and healthier PR practices. Embedding response logic inside CI/CD gives teams quick feedback without extra tools or manual coordination.
4. Automate Communication and Post-Mortem Inputs
Consistent communication keeps incidents under control and makes learning easier afterward. Manual status updates and documentation often fall behind when teams are busy resolving problems, so automation should supply as much structure as possible.
Helpful practices include:
- Automating status page or internal channel updates for major incidents.
- Capturing timelines, affected components, and fix details as incidents unfold.
- Tracking follow-up actions from post-mortems so they reach completion.
Gitar contributes by writing clear commit messages and pull request comments that describe the failure and the applied fix. These records give incident reviewers concrete, code-level evidence without requiring extra note-taking.
The speed of post-incident improvements is a key metric for DevOps ROI and incident-response effectiveness. Automated documentation helps teams move from learning to implementation with less overhead.
5. Build a Self-Healing, Continuously Improving Culture
A self-healing culture treats many incidents as design opportunities. Systems evolve so that common issues resolve automatically, and unusual issues trigger faster, more informed responses.
Foundations for this approach usually include:
- Infrastructure as code and repeatable deployment pipelines.
- Regular reviews of failure patterns and coverage gaps in automation.
- Periodic incident drills to test both tooling and runbooks.
Gitar supports this culture by turning hours of reactive debugging into routine, automated fixes. Visible, successful interventions build trust in automation, and teams can gradually expand the set of scenarios handled without human involvement.
Future-focused DevOps teams are expected to operate systems that self-heal, resolving many issues automatically before engineers open dashboards. CI automation with tools like Gitar is a practical step toward that goal.
Gitar’s Autonomous Approach Compared to Traditional Tools
Manual Incident Response in CI
In a manual model, a failed pipeline forces developers to stop current work, interpret logs, change code, and push new commits. Each incident often consumes 30–60 minutes once context switching and recovery time enter the picture.
Gitar removes most of this workflow. The agent detects the failure, analyzes the cause, applies a fix, and re-runs CI. Developers review the results instead of performing every step themselves.
AI Suggestion Engines Versus Autonomous Resolution
Many AI tools summarize pull requests or suggest edits but depend on developers to apply and validate those edits. Value relies on how much time engineers can spend integrating suggestions.
Gitar focuses on end-to-end resolution. It applies changes, runs the full CI pipeline, and shares the outcome inside the pull request so developers see a passing build, not just a list of proposals.
Comparison Table: Gitar vs Manual and Suggestion-Only Approaches
|
Feature |
Gitar |
Manual/Traditional |
AI Suggestion |
|
Resolution |
Automated, code-level fixes |
Manual, developer-driven changes |
Suggestions or partial automation |
|
Validation |
Full CI validation |
Manual re-runs |
Varies by tool |
|
Developer interruption |
Low |
High context switching |
Varies by tool |
|
MTTR impact for CI issues |
Consistently reduced |
Dependent on individual skills and availability |
Inconsistent |
Frequently Asked Questions About Automated DevOps Incident Response
What Mean Time to Recovery (MTTR) tells DevOps teams
MTTR measures how long it takes to restore service after an incident. Lower MTTR signals stronger resilience, faster response, and better user experience. It reflects the combined effectiveness of detection, diagnosis, remediation, and validation across tools and teams.
How Gitar reduces context switching for engineers
Gitar handles CI failures and review feedback directly on pull requests. The agent inspects failures, edits code, and commits fixes, so developers can stay focused on feature work instead of repeatedly pausing to debug pipelines.
How Gitar works in complex CI environments
Gitar supports complex enterprise setups by replicating the CI environment, including specific SDK versions, multi-language dependencies, and tools such as SonarQube or Snyk. This context helps the agent generate fixes that align with real builds rather than generic code examples.
Conclusion: Moving Toward Automated DevOps Incident Response in 2026
Manual incident response in CI/CD no longer matches the pace of modern development. Monitoring improvements, autonomous agents, deeper workflow integration, stronger communication, and a self-healing culture form a practical roadmap to lower MTTR and reduce interruptions.
Gitar gives teams a focused, autonomous layer for CI and code review issues. By automatically fixing many failures and documenting its actions, it helps teams move from reactive firefighting to predictable, reliable delivery.