Key Takeaways
- 2026 benchmarks show AI code review tools average 90% syntax detection but only 65% logic flaw detection, with 20-30% false positives.
- Gitar leads with validated auto-fixes through its healing engine and guarantees green builds, unlike suggestion-only competitors.
- Teams using Gitar report 75% faster PR reviews and $750K annual savings for 20-developer groups.
- Experience true automation beyond suggestions by starting your 14-day free Team Plan trial with Gitar.
Developer Pain in 2026: AI Code Review Accuracy Gaps
AI code review accuracy still falls short for real-world bugs. Syntax detection reaches 85-95% accuracy, but logic flaws drop to 50-80% because models struggle with contextual reasoning.
Developer feedback on Reddit reflects this reality. Many engineers say, “Noisy PRs kill velocity.” The constant stream of notifications from scattered inline comments creates alert fatigue and hides critical issues under cosmetic noise.
Gitar reduces this noise with single-comment summaries that update in place. Teams at Tigris and Collate report that Gitar’s approach is “more concise than Greptile/Bugbot,” because it consolidates all findings into one clean dashboard comment. Start your 14-day free Team Plan trial to cut notification spam and keep focus on real issues.
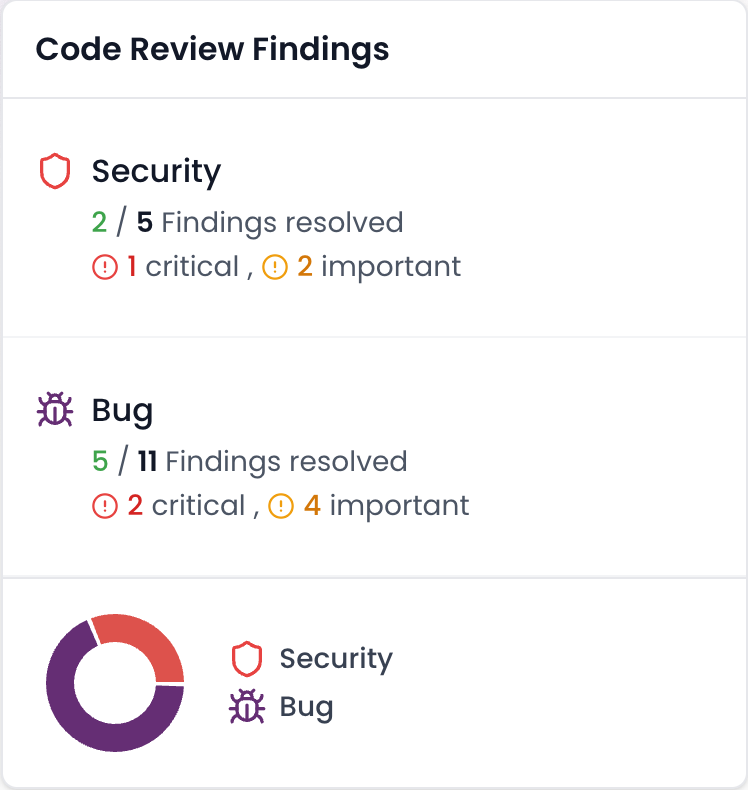
Start your 14-day free Team Plan trial to see how context-aware analysis improves accuracy.
False Positives in AI Code Review: Controlling the Noise
Untuned SAST tools commonly produce 30-60% false positives. Teams often abandon tools when every PR gets flagged for dozens of non-issues, because reviews become slower and more frustrating.
Repository-level context significantly reduces this noise. Repository-wide context reduces false positives by 51% compared to file-by-file analysis. Gitar maintains context per line, per PR, and per repository, and it learns team patterns over time to avoid repeating the same false alarms.
Real-world validation proves the impact of this approach. Gitar’s healing engine caught a high-severity security vulnerability in Copilot-generated code that Copilot itself missed, which shows how different architectures produce different results. Start your 14-day free Team Plan trial to see validated accuracy in your own CI.
Top AI Code Review Tools Ranked by Accuracy and Fix Power
Validated auto-fixing now separates basic AI reviewers from production-ready automation.
|
Rank/Tool |
Auto-Fix |
CI Validation |
Green Build Guarantee |
|
#1 Gitar |
Yes |
Yes |
Yes |
|
#2 Paragon |
No |
No |
No |
|
#3 CodeRabbit |
No |
No |
No |
|
#4 Greptile |
No |
No |
No |
Gitar leads through its healing engine workflow. When CI fails, it analyzes failure logs, generates fixes with full codebase context, validates that those fixes work, and commits them automatically. The platform supports GitHub Actions, GitLab CI, CircleCI, and Buildkite with coverage across multiple languages.
Competing tools stop at suggestions. Developers still read comments, apply changes by hand, push new commits, and wait to see whether CI passes. This small improvement rarely justifies $15-30 per developer each month when manual work still dominates the workflow. Start your 14-day free Team Plan trial to experience true automation instead of assisted manual review.
Gitar’s Healing Engine: Accuracy and Automation Combined
The healing engine turns CI failures into automatic resolutions. When lint errors, test failures, or build breaks occur, Gitar analyzes root causes, generates validated fixes, and commits solutions before developers even open the PR. This closes the gap between suggestions and real implementation.
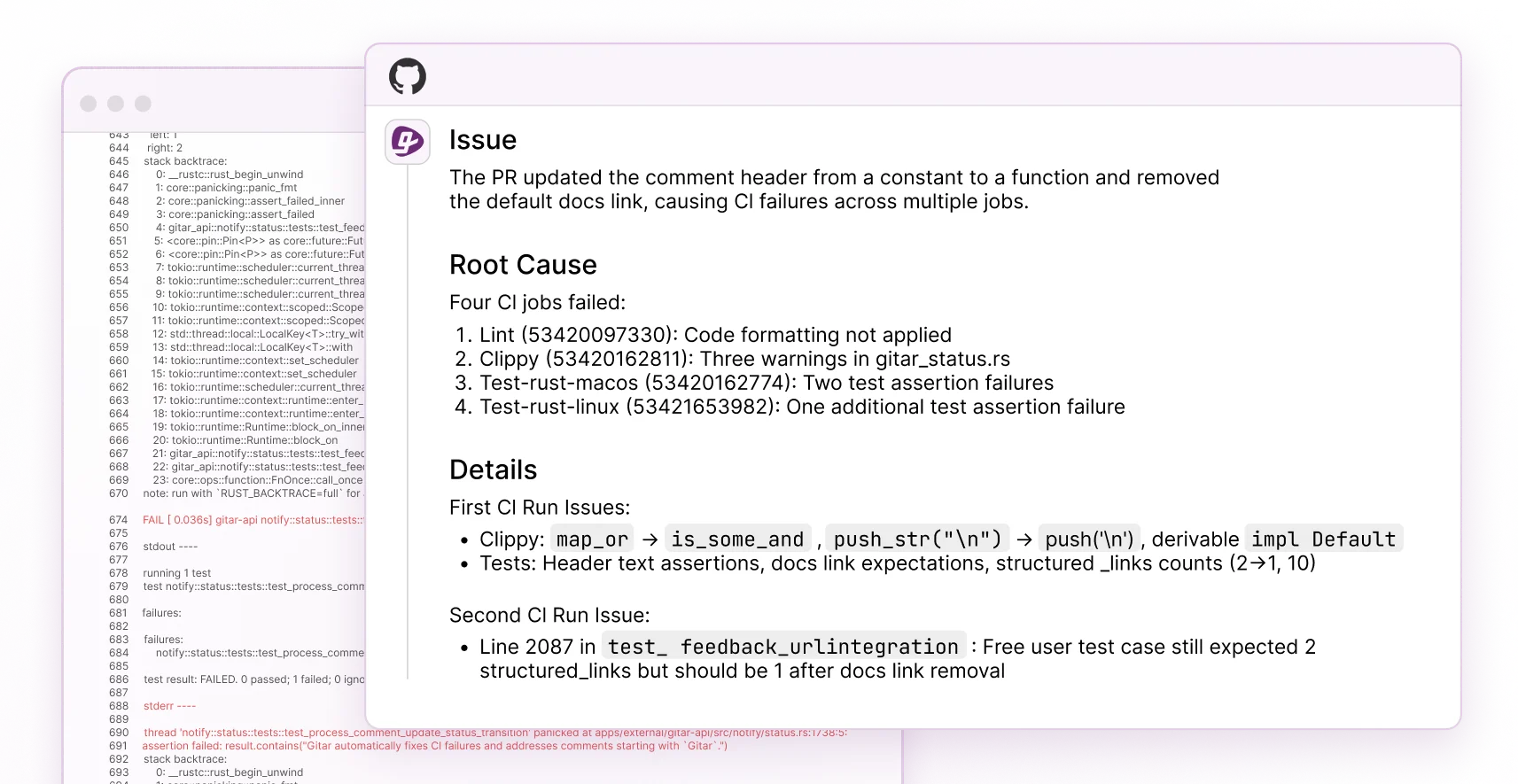
Teams report $750K annual savings for 20-developer groups through fewer context switches and faster merge cycles. Collate’s engineering lead highlighted “unrelated PR failure detection,” saving “significant time” by separating infrastructure flakiness from actual code bugs, a distinction traditional reviewers rarely make consistently.
Setup takes 30 seconds with the GitHub App installation, which immediately posts dashboard comments on PRs. Natural language rules in .gitar/rules/*.md enable workflow automation without YAML complexity or long configuration files.
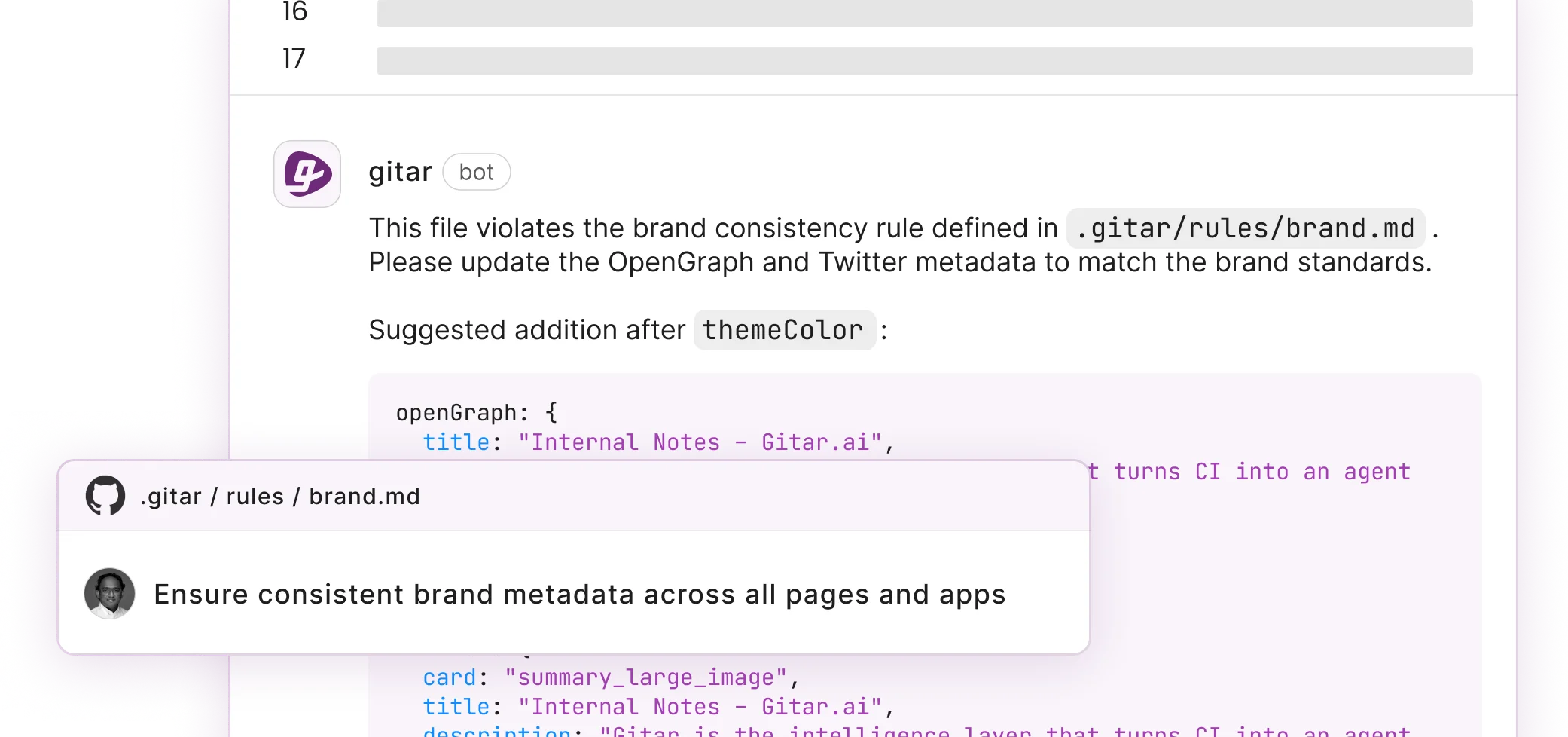
ROI, Metrics, and Best Practices for AI Code Review
Hybrid AI and human review delivers the strongest results for most teams. AI handles routine syntax, style, and pattern checks, while humans focus on architecture, business logic, and edge cases. Key metrics include reduced time-to-first-review, fewer review iterations per PR, and decreased escaped defects.
|
Metric |
Before Gitar |
After Gitar |
|
PR Review Time |
91% increase |
75% reduction |
|
Annual Savings (20-dev team) |
$1M productivity loss |
$750K recovered |
|
Context Switching |
Multiple daily interrupts |
Near-zero |
2026 trends point toward autonomous review as the new standard. Teams that adopt validated auto-fixing gain faster delivery cycles and slow technical debt growth, which compounds into a long-term competitive advantage.
FAQs
How accurate is AI code review in 2026?
AI code review accuracy varies significantly by category. Syntax detection reaches 85-95%, but logic flaw detection drops to 50-80%. False positive rates of 20-30% create noise that reduces effectiveness. Gitar improves practical accuracy with deeper context awareness and validation through its healing engine.
What is the difference between AI code review suggestions and auto-fixes?
Most AI tools suggest fixes in comments, so developers must manually implement changes and hope they work. Gitar’s healing engine generates fixes, validates them against CI, and commits working solutions automatically. This approach closes the suggestion-to-implementation gap that keeps teams stuck in manual workflows.
How reliable is AI-generated code review for production use?
Reliability depends on strong validation mechanisms. AI-generated PRs contain 1.7x more issues than human code, which makes validation critical for production. Gitar validates all fixes against actual CI environments before committing, which ensures green builds. Suggestion-only tools leave validation to developers and reduce overall reliability.
Which AI code review tool offers the strongest mix of accuracy and automation?
Gitar leads with validated auto-fixes and green build guarantees. Competing tools often charge $15-30 per seat for suggestions that still require manual work. Gitar focuses on fixes that actually work in CI. The 14-day free Team Plan trial lets teams experience this difference without risk.
How does the 14-day free trial work?
The Team Plan trial includes full access to auto-fix capabilities, custom rules, and CI integration across GitHub Actions, GitLab CI, CircleCI, and Buildkite, plus Jira and Slack integrations. The trial has no seat limits, so entire teams can participate. Teams can measure velocity improvements and review quality before choosing a paid plan.
Conclusion: From AI Suggestions to AI Solutions
AI code review accuracy in 2026 shows a clear divide between tools that suggest and tools that solve. Syntax detection reaches 85-95% across platforms, while logic detection lags at 50-80% and false positive rates often reach 20-30%. Validated auto-fixing that guarantees green builds now matters more than raw detection scores.
Gitar’s healing engine removes the code review bottleneck by fixing problems instead of only identifying them. Teams see proven ROI, including $750K annual savings for typical 20-developer groups. Start your 14-day free Team Plan trial to experience the difference between AI suggestions and AI solutions in your own pipeline.