
Key Takeaways
- Automated rollback reduces downtime and hidden costs by restoring services quickly when deployments fail.
- Clear triggers, metrics, and deployment patterns such as blue-green and canary improve rollback reliability and predictability.
- Robust rollback design must include database state management, observability, and regular testing under realistic failure conditions.
- Organizational readiness, shared ownership, and clear success metrics are as important as tooling for effective automated rollback.
- Gitar provides autonomous CI and rollback support, helping teams fix broken builds and recover faster without disrupting developer focus, so teams can ship reliable software with greater confidence.
The Strategic Imperative: Why Automated Rollback is Non-Negotiable
Deployment failures carry direct revenue loss and significant hidden costs. Enterprise downtime often ranges from £8,000 per hour for small businesses to £4 million per hour for large organizations, before factoring in productivity loss, emergency coordination, and customer trust damage.
Modern teams ship faster than ever, which increases exposure to deployment risk. As AI-assisted coding accelerates development, validation and safe deployment now limit throughput. Automated rollback becomes a core capability for scaling delivery while controlling risk.
Common Causes of Deployment Failure
Teams that understand failure patterns can design better rollback strategies. Frequent causes include undetected code bugs, configuration mistakes, database migration issues, dependency mismatches, real-world scaling problems, and security policy conflicts.
These patterns are predictable and suitable for automation. Well-designed rollback workflows convert deployment issues from emergencies into routine, low-friction recovery steps.
Understanding Automated Rollback: Concepts, Triggers, and Architecture
What Is Automated Rollback?
Automated rollback replaces manual crisis response with predefined recovery actions. Systems monitor deployments continuously and revert to a known good version when health signals cross agreed thresholds.
Typical components include Git-based version control with tags, automated deployment scripts, monitoring tools such as Prometheus, and rollback triggers tied to test or health check failures. Together, these elements shorten recovery time and reduce reliance on manual intervention.
Key Rollback Triggers and Metrics
Effective rollback logic relies on clear, measurable triggers. Many teams use thresholds such as error rate spikes exceeding 5 percent within the first 10 minutes after deployment.
Broader monitoring often includes fault rates, latency, CPU, memory, disk utilization, and log error patterns. Composite metrics that blend service-level and instance-level signals help distinguish real incidents from short-lived noise.
Core Components of a Rollback Strategy
Reliable rollback depends on tight integration between CI/CD, infrastructure, and monitoring. Common setups combine tools like GitHub Actions, GitLab CI/CD, Jenkins, and Terraform with versioned artifacts and deployment automation.
Engineering leaders should treat rollback as part of business continuity planning. Coordination between SRE, product, and support teams ensures that technical rollback rules align with customer and business priorities.
Deployment Patterns that Enable Fast, Safe Recovery
Blue-Green Deployments for Instant Rollback
Blue-green deployments keep two identical environments and route traffic only after health checks pass. If problems appear, traffic switches back to the previous environment in seconds.
This pattern suits teams that prioritize minimal downtime and can afford duplicate infrastructure. It offers simple rollback behavior at the cost of higher resource usage.
Canary Deployments for Gradual Rollback
This approach limits blast radius and yields detailed performance data, though it introduces more complexity in traffic routing and monitoring logic compared with blue-green.
The Role of Immutable Infrastructure
Immutable infrastructure improves rollback by ensuring that deployments replace entire units rather than updating them in place. Combined with containers and infrastructure as code, this approach reduces configuration drift and makes rollbacks predictable.
Gitar: Your Autonomous Partner for Automated Rollback
The Self-Healing Pipeline with Gitar
Gitar focuses on preventing many rollback events before they reach production. Its autonomous agent fixes CI issues such as failing tests, lint errors, and broken builds so unstable code does not ship.
This shift from reactive recovery to proactive prevention lowers incident volume and frees teams to focus on feature work instead of firefighting.
How Gitar Supports Automated Rollback Strategies
Gitar operates in complex CI/CD environments with concurrent jobs, asynchronous events, and multi-step workflows. The agent maintains context across jobs and users, so fixes and rollbacks respect current development activity.
Replication of production-like environments allows Gitar to validate fixes against real dependencies, SDK versions, and third-party integrations. This approach reduces the risk that a rollback or hotfix fails in production.
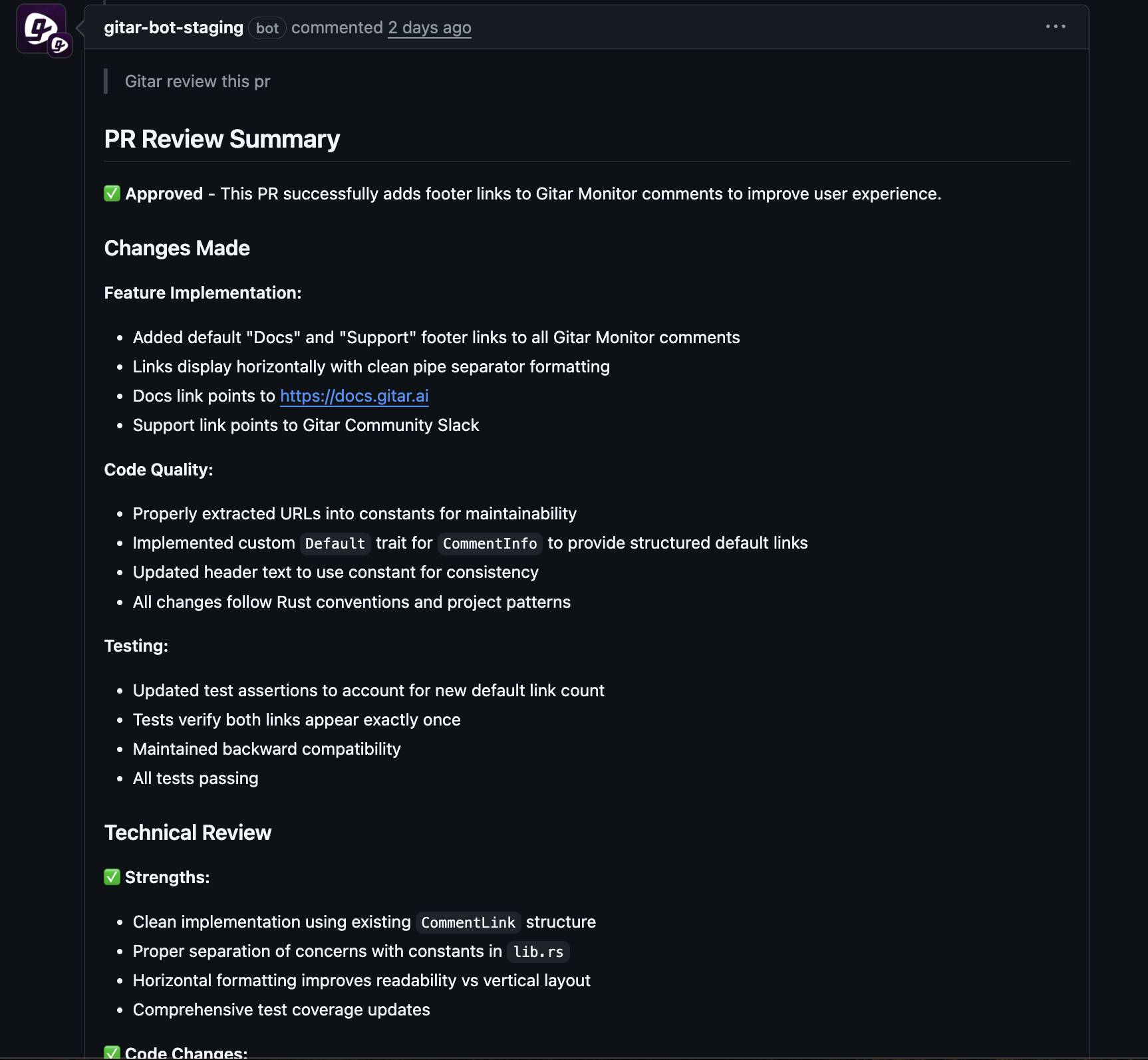
Preserving Developer Flow with Autonomous Fixes
Rollback events often interrupt developers with urgent investigations and coordination calls. Gitar minimizes these interruptions by handling much of the failure analysis and remediation automatically.
Distributed teams benefit in particular. Instead of late-night incidents, many issues resolve autonomously while teams stay focused on planned work.
Implementing Automated Rollback in Your CI/CD Pipeline
Selecting the Right Tools for Integration
Tooling should provide clear observability into why a rollback happened and what signals triggered it. That transparency supports continuous tuning of thresholds and playbooks.
Designing Robust Rollback Logic
Rollback logic must account for dependencies across services, databases, and external APIs. Many teams include an observation window after deployment before declaring success.
This period helps surface issues such as memory leaks, resource contention, or integration failures that only appear under real traffic.
Database State Management During Rollbacks
Automated database snapshot backups before each deployment provide a safety net for data-related failures. However, rolling back databases can risk losing post-deployment transactions.
Forward-compatible migrations, feature flags, and patterns such as dual writes can reduce the need for full database rollbacks while maintaining data integrity.
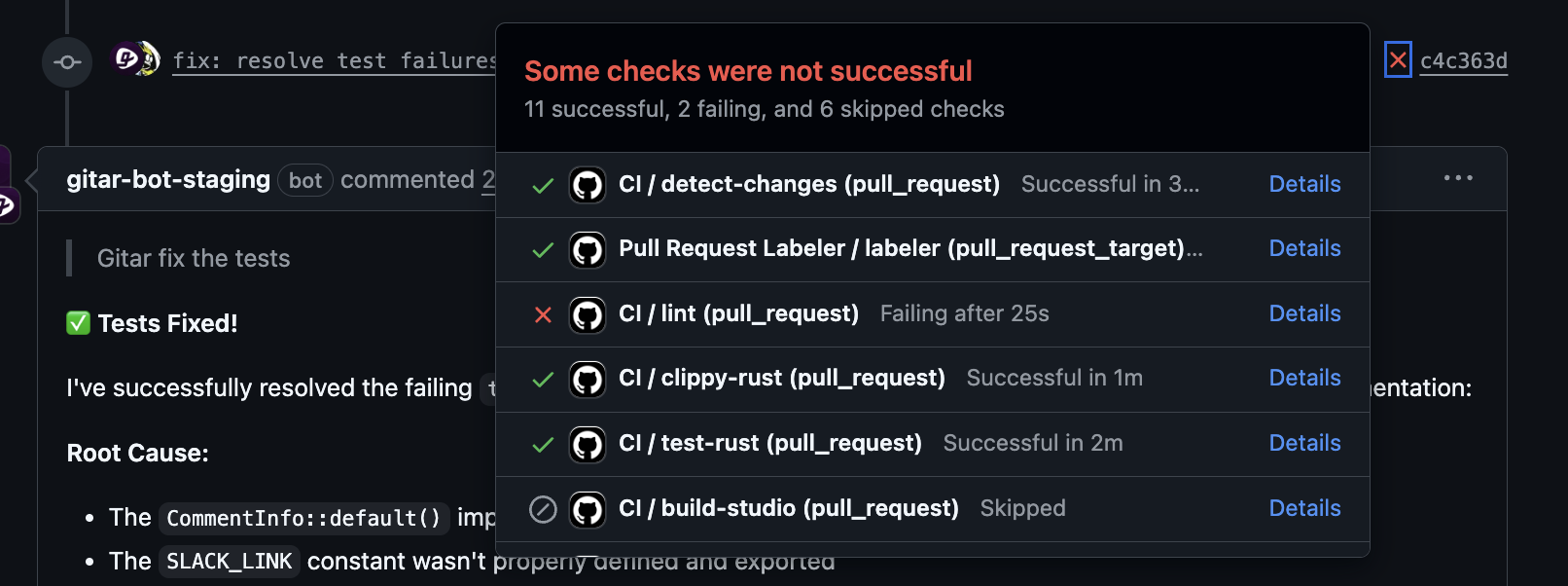
Implement Gitar to cut rollback frequency by preventing CI failures from reaching production.
Strategic Considerations and Avoiding Common Pitfalls
Organizational Readiness and Adoption
Automated rollback works best when product and engineering collaborate on criteria for success and failure. Product Managers and Product Owners should define rollback implications during planning, not during emergencies.
This alignment ensures that technical rollbacks do not conflict with contractual obligations, launch plans, or customer expectations.
Testing Your Automated Rollback Strategy
Regular, realistic rollback drills validate that automation behaves as designed. These exercises uncover integration gaps and build team confidence.
Clear runbooks and playbacks after each drill help teams refine both tooling and process.
Calculating ROI and Defining Success Metrics
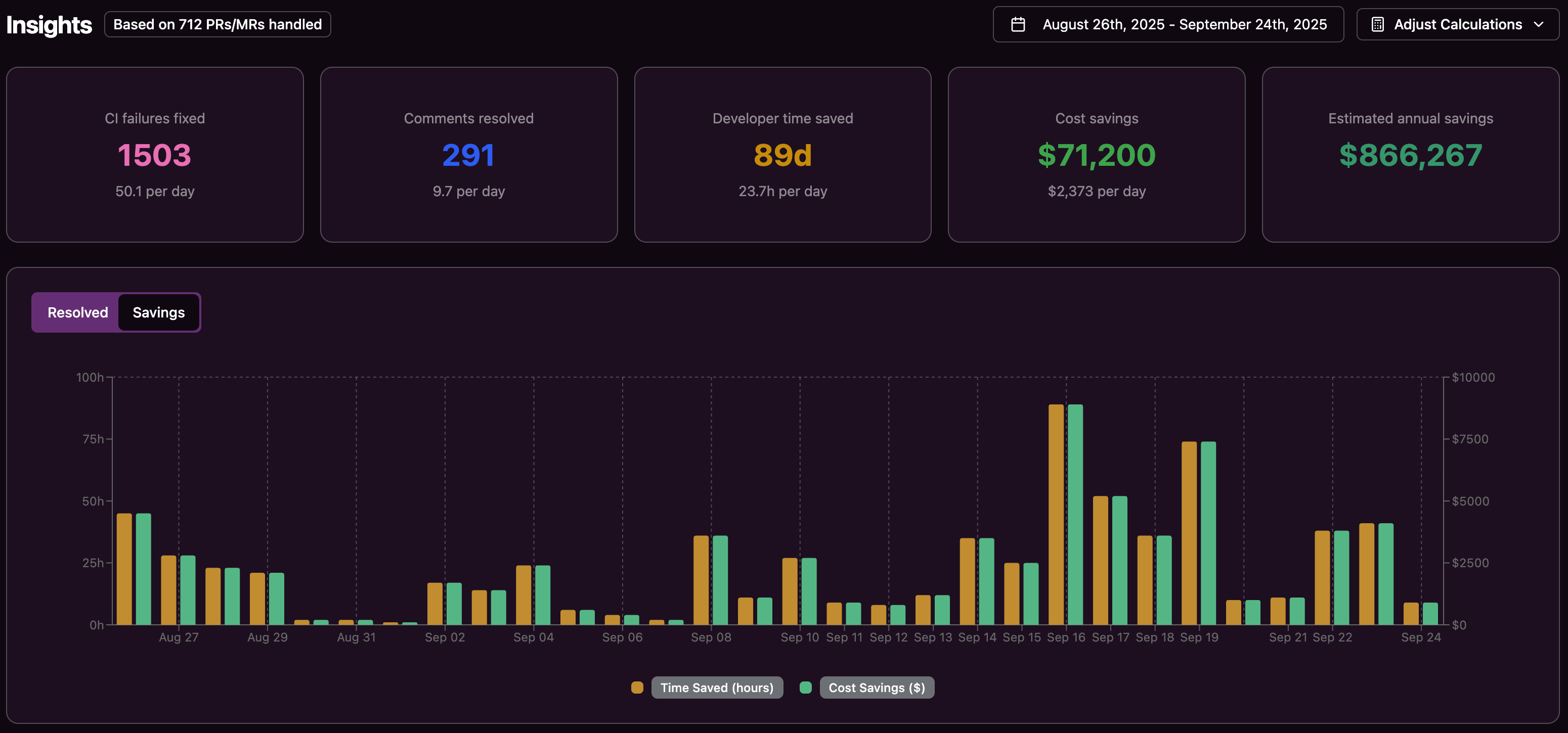
Automated rollback delivers value through reduced downtime, faster recovery, and higher developer productivity. Key metrics include MTTR, deployment frequency, time spent on incident response, and customer incident reports.
Tracking these indicators over time shows how rollback improvements and tools such as Gitar affect both technical performance and business outcomes.
Frequently Asked Questions
How much does downtime cost, and how does automated rollback help?
Downtime can cost from thousands to millions of pounds per hour, depending on company size. Automated rollback reduces MTTR from hours to minutes by restoring the last known good version without lengthy diagnosis, which limits revenue loss and lowers the operational burden on teams.
What are the key differences between blue-green and canary deployments?
Blue-green deployments favor instant rollback by switching all traffic between two identical environments, which simplifies recovery but doubles infrastructure needs. Canary deployments expose a small share of users to the new version first, use metrics to validate behavior, and then scale up or roll back gradually, which reduces risk per change but requires more sophisticated routing and monitoring.
How does Gitar reduce interruptions for developers?
Gitar analyzes CI failures, identifies likely root causes, and applies fixes automatically where appropriate. This automation reduces the need for urgent log analysis, local reproduction of issues, and repeated manual fixes, which preserves developer focus and cuts time lost to unplanned work.
Can automated rollback systems handle database inconsistencies?
Effective systems pair automated rollback with strong data strategies. Database snapshots, forward-compatible schema changes, and approaches such as event sourcing or change data capture provide options for restoring application behavior while protecting business data. Teams still need clear policies for when to roll back data, when to apply forward fixes, and how to verify integrity after recovery.
Conclusion: Building a Reliable Deployment Culture with Automated Rollback
Automated rollback has become a core requirement for teams that deploy frequently and value stability. Rollback works best when treated as a default part of the delivery process rather than an emergency-only option.
Engineering leaders who invest in clear triggers, safe deployment patterns, strong data practices, and regular testing create a culture where teams can ship quickly without accepting high risk.
Gitar extends these practices across the CI/CD pipeline by fixing many issues before they reach production and supporting faster, more predictable recovery when failures occur. Install Gitar to add autonomous CI fixes and intelligent rollback support to your delivery process.