
Key Takeaways
- Staging environments act as production-like proving grounds where integration, end-to-end, performance, and security tests reduce the risk of failed deployments.
- Pre-merge CI in staging runs many more checks than post-merge pipelines and fails more often, so optimization here has the largest impact on developer productivity.
- Common issues such as flaky tests, resource exhaustion, and complex dependencies create frequent CI failures that disrupt developer focus and delay releases.
- Autonomous, self-healing CI systems use AI agents to analyze failures, apply targeted fixes, and restore passing builds with less manual intervention.
- Teams can reduce interruptions from pull request failures and keep developers in flow by using an autonomous fixer like Gitar to automatically resolve CI issues in staging.
The Critical Role of Staging Environments in Modern CI/CD
Staging environments validate code changes under conditions that closely resemble production. They mirror infrastructure, data patterns, and third-party integrations so teams can catch issues before they affect users.
Pre-merge CI/CD phases run about 15 times more checks than post-merge phases. This heavy concentration of testing makes staging a key factor in release speed and reliability.
Staging environments support several high-value test types:
- Integration tests to confirm services and components work together.
- End-to-end tests to validate full user flows.
- Performance tests to assess latency and throughput under load.
- Security scans to surface vulnerabilities early.
Reliable results from these tests depend on production-like fidelity and stable, well-managed staging infrastructure.
The Unseen Costs of Interrupted Testing: Why Traditional Approaches Fall Short
CI failures in staging do more than slow a single pull request. They reduce effective engineering capacity. Developers can spend up to 30% of their time on CI and code review issues, which can equal hundreds of thousands of dollars per year for a mid-size team.
Context switching increases the impact. A developer often moves on after opening a pull request. When staging CI later fails, attention shifts back to logs, configs, and tests. This shift can turn a brief fix into a long interruption that breaks deep focus.
Several recurring problems drive these failures:
- Flaky tests and intermittent issues contribute heavily to CI/CD job failures.
- Test, build, and dependency misconfigurations add avoidable breaks.
- Around 63% of pipeline failures stem from resource exhaustion, including CPU, memory, or storage limits.
Repeated failures and re-runs erode flow state. Over time, this pattern can reduce satisfaction, increase burnout risk, and slow delivery.
Architectural Best Practices for Optimized Staging Environments
Replicating Production Fidelity
High-fidelity staging environments include the same core elements as production:
- Aligned server and container configurations.
- Consistent database schemas and key datasets.
- Matching network topologies, routing, and security rules.
- Realistic integrations with third-party services and internal APIs.
This alignment improves confidence that passing tests in staging will behave the same way in production.
Ephemeral Environments
Short-lived, per-branch staging environments isolate changes and encourage parallel work. Teams can spin up a fresh environment for each pull request, run tests, and dispose of it after review.
This approach reduces cross-PR interference, prevents configuration drift, and uses infrastructure resources more efficiently.
Data Masking and Security
Staging environments benefit from realistic data, but production data often includes sensitive information. Safer setups use:
- Data masking to obfuscate personal or confidential fields.
- Synthetic or sampled datasets for specific scenarios.
- Role-based access controls that limit who can view or modify data.
These measures maintain compliance while preserving test quality.
Monitoring and Observability
Effective CI/CD monitoring tracks pipeline metrics and infrastructure health. Useful signals for staging include:
- CPU, memory, and disk utilization on build agents.
- Build duration and queue time.
- Test pass rates and flakiness trends.
- Network latency between key services, ideally under 50 ms.
Alerts for sustained high resource usage or sudden drops in success rate help prevent cascading failures.
Prioritizing Pre-Merge Optimization
Teams with limited time or budget gain the most by optimizing pre-merge testing first. Developers experience the sharpest productivity impact from pre-merge job failures and long waits, so fixes here directly improve daily workflow.
Introducing Self-Healing CI: Autonomous AI’s Role in Staging Environment Stability
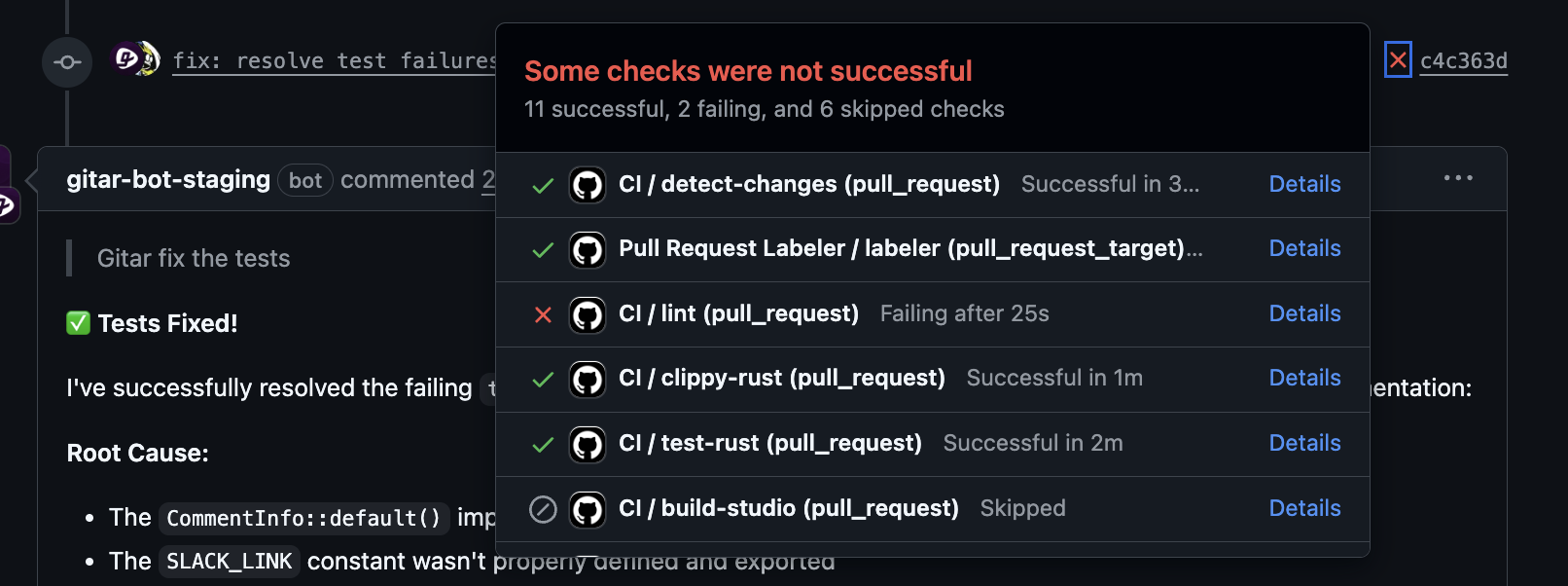
Self-healing CI uses autonomous AI agents to detect and fix CI failures in the background. When lint checks, tests, or build steps fail, the agent reviews logs, identifies likely causes, proposes changes, and applies verified fixes to the pull request branch.
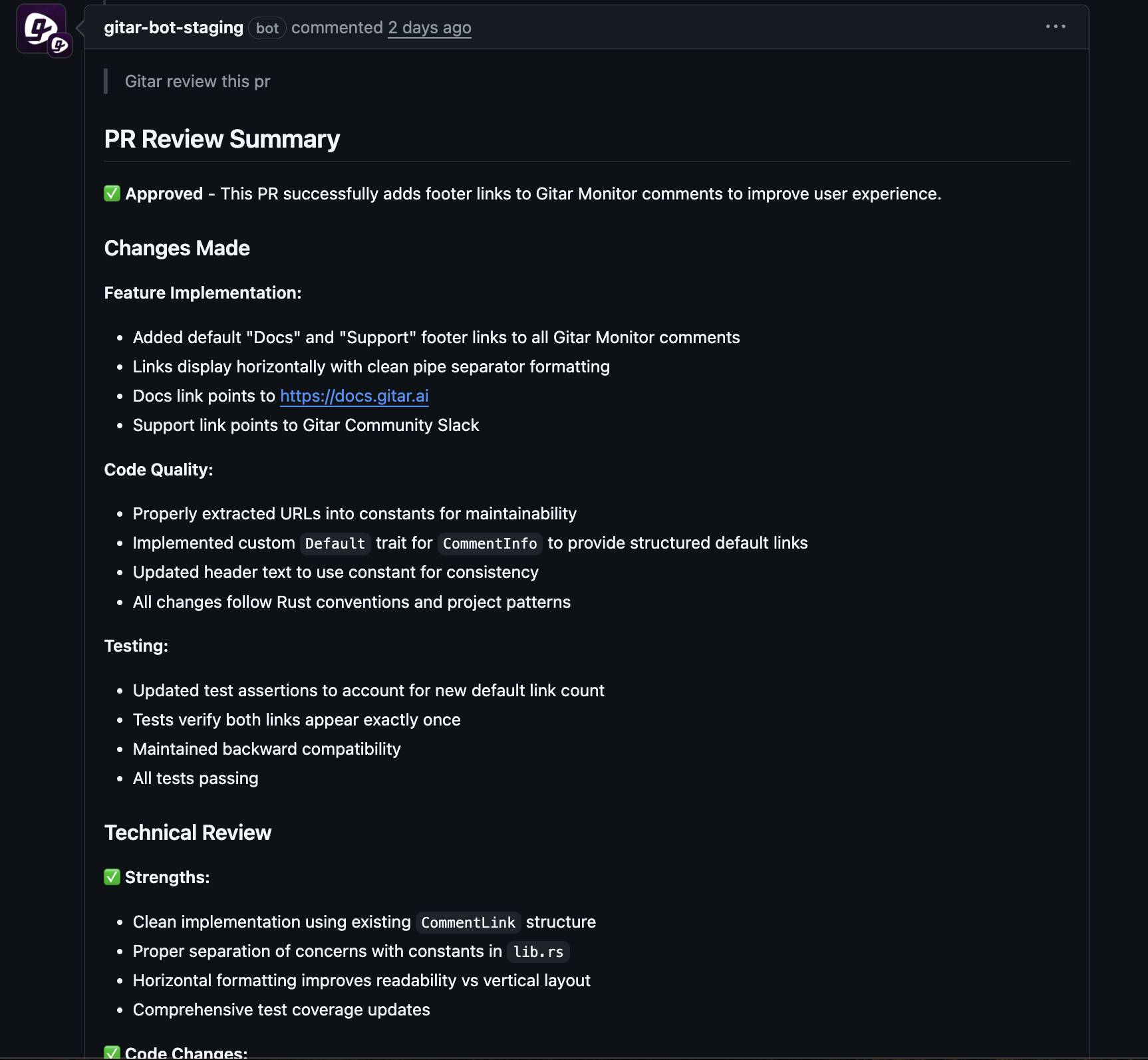
Modern agents incorporate environment-specific context so fixes account for particular frameworks, infrastructure, and dependencies. This context reduces the chance that a change passes unit tests but fails in staging.
CI failures then shift from disruptive events to automated maintenance tasks. Developers remain focused on feature work while the agent handles common errors and re-runs pipelines.
Teams that want this experience can adopt an autonomous fixer such as Gitar to keep staging pipelines healthy with less manual effort.
Implementing Advanced Staging Strategies with AI-Powered Fixation
Phased Rollout of Autonomous AI
Gradual rollout builds trust and reduces risk. A typical path looks like this:
- Suggestion mode: The AI posts proposed fixes as comments or patches, and developers review and apply them manually.
- Guarded auto-commit: The AI commits certain categories of fixes, such as lint or formatting changes, while leaving complex changes for review.
- Broader automation: The AI automatically fixes a wider range of issues, with clear logs and an easy rollback process.
Measuring Success: Key Metrics for Staging Environment ROI
Clear metrics help demonstrate the value of self-healing CI in staging:
- Build failure rate, or the percentage of failed builds, indicates stability.
- Mean Time To Recovery for failed pipelines shows how quickly issues get resolved.
- CI/CD Pipeline Success Rate reflects how often pipelines complete without error.
- Change Failure Rate tracks how many deployments require remediation; high-performing teams often maintain 10–20%.
Teams can also estimate hours saved from reduced manual debugging and fewer context switches.
Strategic Integration with GitOps
GitOps practices use Git as the single source of truth for infrastructure. When paired with autonomous CI fixing, teams gain:
- Version-controlled infrastructure and application changes.
- Repeatable, auditable updates across staging and production.
- Automated remediation when infrastructure or configuration changes break pipelines.
Self-healing CI agents then operate within a clear, declarative model, reducing configuration drift.
Comparing Solutions: Autonomous AI vs. Traditional Approaches and Suggestion Engines for Staging Environments
Teams can choose between autonomous healing engines, suggestion-only tools, and manual debugging. Each option carries different tradeoffs for staging environments.
|
Feature |
Autonomous AI (Healing Engine) |
AI Suggestion Engines |
Manual Debugging |
|
Fixes CI Failures |
Applies and validates fixes in staging pipelines |
Suggests changes; developers apply and validate |
Relies on manual investigation and edits |
|
Targets Green Builds |
Runs full workflows to confirm passing CI |
Does not guarantee success across full pipeline |
Requires repeated manual runs until success |
|
Works With Complex CI Setups |
Uses environment context across services and platforms |
Often limited to specific providers or contexts |
Effort grows quickly with complexity |
|
Impact on Developer Flow |
Minimizes interruptions through background operation |
Requires frequent manual review and action |
Continuously interrupts focus for debugging |
AI suggestion engines such as CodeRabbit focus on review feedback, not on closing the loop with passing staging runs. On-demand AI fixers also require manual triggering and can consume CI resources without guaranteeing a complete fix.
Autonomous tools aim to analyze failures, propose changes, and verify results in a single loop, which makes them better suited for complex staging environments.
Frequently Asked Questions About Staging Environments and Self-Healing CI
How does an autonomous AI agent differ from traditional AI code review tools for comprehensive testing in staging environments?
Traditional tools surface potential issues and suggestions but stop short of fixing failing pipelines. An autonomous agent acts as a healing engine that updates code, configuration, or tests, then re-runs CI to confirm that staging builds pass.
Our existing CI/CD pipelines for staging environments are complex with many dependencies. Can autonomous AI integrate effectively without major refactoring?
Many autonomous AI tools emulate project dependencies, SDK versions, and environment variables used in staging. They typically integrate with common systems such as GitHub Actions, GitLab CI, CircleCI, and BuildKite without requiring a full pipeline redesign.
What metrics should engineering leaders track to measure the impact of implementing autonomous AI for comprehensive testing in our staging environments?
Leaders can track pre-merge build failure rate, Mean Time To Recovery for CI incidents, pipeline success rate, and change failure rate. Time saved per engineer from reduced debugging and fewer context switches also provides a useful benchmark.
How can autonomous AI contribute to reducing interruptions from pull request build failures, especially during the pre-merge phase in staging?
Autonomous AI tools inspect failing jobs, apply targeted fixes on pull request branches, and re-run tests. Many failures resolve before the developer returns to the PR, which reduces notifications, manual log reviews, and context switching.
What makes staging environments particularly challenging for traditional CI fixing approaches?
Staging environments combine multiple services, databases, and integrations that must work together. Generic fixes that succeed in isolated tests may fail in this broader context. Autonomous AI with environmental awareness tailors fixes to real staging conditions.
Conclusion: Reclaiming Developer Productivity with Self-Healing Staging Environments
Faster, more reliable pipelines give teams room to ship more often. Teams with fast pipelines deploy about twice as frequently as teams with slow pipelines, which supports quicker feedback and iteration.
Staging environments that mirror production, combined with self-healing CI, reduce the drag from flaky tests, misconfigurations, and resource limits. Unresolved pipeline issues often signal wasted resources and missed opportunities, so addressing them delivers both technical and organizational benefits.
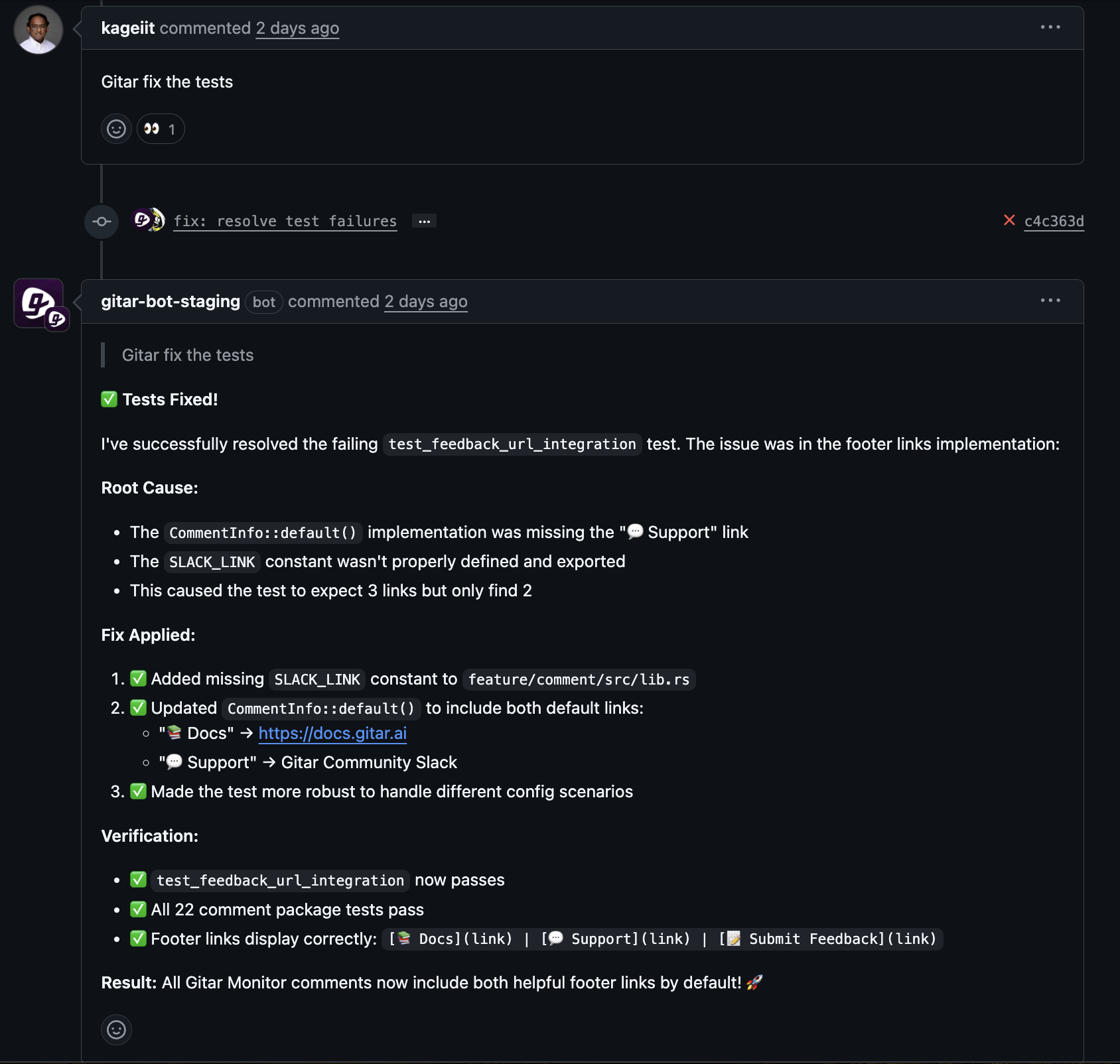
Teams that want to reduce interruptions from pull request build failures and keep developers focused can adopt an autonomous fixer such as Gitar to automatically repair broken builds in staging and support more reliable releases.