Written by: Ali-Reza Adl-Tabatabai, Founder and CEO, Gitar
Key Takeaways for Reducing False Positives
- AI coding tools speed up coding but slow reviews, with PR review time up 91% because traditional SAST tools generate 80-90% false positives.
- Contextual AI analysis and framework-aware tuning cut false positives by tracking data flows and understanding framework behavior.
- Custom rules, severity thresholds, and feedback loops such as “not a bug” buttons tune tools to your codebase and reduce noise significantly.
- Teams reduce wasted time by separating CI flakiness from real bugs and choosing tools that focus on deep codebase analysis.
- Gitar autonomously fixes CI failures with validated commits. Install Gitar’s 14-day trial to guarantee green builds and reclaim developer productivity for a 20‑developer team.
Introducing Gitar: Autonomous Fixes Instead of Comment Spam
Gitar replaces suggestion-only tools that leave comments and extra work. The Healing Engine analyzes CI failures, auto-generates validated fixes, and commits them directly to your PR. This workflow delivers real fixes through context-aware validation across GitHub, GitLab, CircleCI, and Buildkite. For implementation details, see the Gitar documentation.
Key capabilities include auto-applying fixes that actually work, CI auto-resolution with validation, natural language rules in .gitar/rules/*.md files, and hierarchical memory that learns per-line, per-PR, per-repo, and per-organization patterns. The Gitar documentation details the complete platform architecture. The table below shows how these capabilities translate into concrete advantages over suggestion-only tools.
|
Capability |
CodeRabbit/Greptile |
Gitar |
Benefit |
|
Auto-apply fixes |
No |
Yes |
Green builds guaranteed |
|
CI validation |
No |
Yes |
Validated fixes |
|
Single comment |
Noisy spam |
Yes |
No notification overload |
|
Trial access |
$15-30/dev |
14-day Team Plan, unlimited |
Prove ROI first |
Start your 14-day trial to see how Gitar’s autonomous fixes compare to suggestion-only tools.
The 80-90% false positive rate in traditional SAST tools comes from several gaps in how they analyze and prioritize findings. The seven tactics below address those gaps and show how modern platforms, including Gitar, reduce noise while preserving real bug detection.
Seven Tactics to Eliminate False Positives
1. Contextual AI Analysis Across Code and Product
Modern SAST tools with AI-assisted analysis and context-aware findings have led to significant reductions in false positives by modeling data flows and focusing on real-world exploitability. Advanced 2026 LLM architectures use hierarchical memory systems that counter confirmation bias when reviewing AI-generated code.
Effective contextual analysis pulls information from Jira and Linear so the system understands the “why” behind changes, not only the code diffs. This product context helps separate intentional architectural decisions from actual bugs. The system also needs to detect infrastructure flakiness versus real code issues by analyzing failure patterns across multiple runs, or else environmental problems get flagged as code defects.
How Gitar Delivers: Tigris engineering teams report Gitar’s PR summaries are “more concise than Greptile/Bugbot” because the platform pulls product context and maintains organizational memory, which prevents repetitive flags on known patterns.
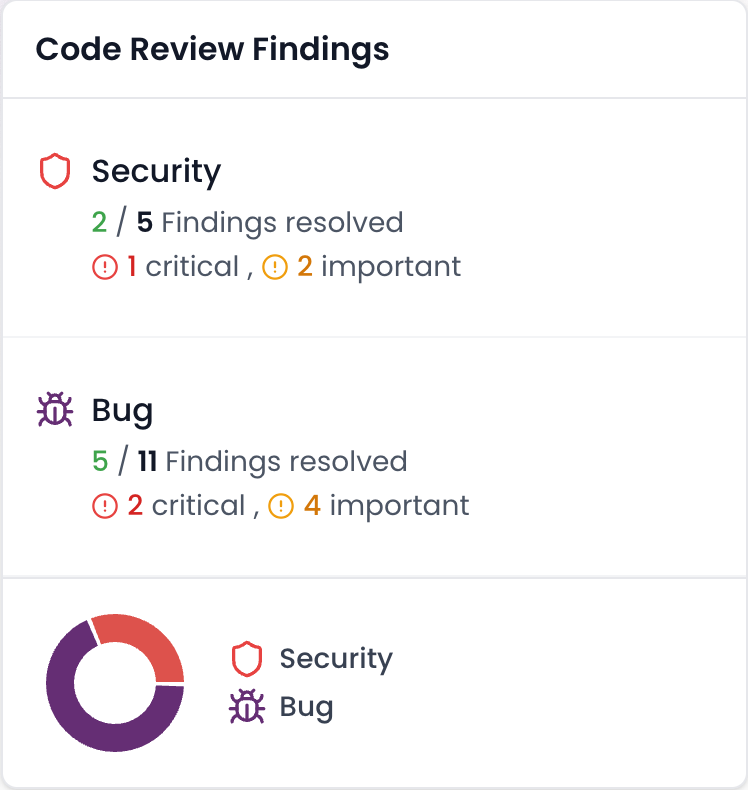
Context alone does not cover every source of noise. The AI must also understand the specific frameworks and libraries in use so it can avoid flagging behavior that the framework already secures.
2. Framework-Aware Tuning for Realistic Findings
Language-specific LLMs trained on Python, JavaScript, and Go codebases recognize framework behaviors that generic models miss. Semgrep offers framework-specific rule packs for Django, Flask, Spring, Express, and Rails that understand behaviors such as auto-escaping in render_template(), which reduces false positives compared to generic packs.
Gitar’s Approach: Gitar’s security review agent caught a high-severity vulnerability in Copilot-generated code that Copilot itself missed. This result shows deeper framework-aware analysis that goes beyond surface-level pattern matching.
The first two tactics focus on how the AI analyzes code. The next two focus on how you configure that analysis so it reflects your team’s priorities and existing technical debt.
Configuration Tactics That Reduce Noise
3. Custom Rules and CI Integration That Match Your Workflow
Natural language rules in .gitar/rules/*.md files let teams specify “ignore lint errors in legacy dependencies” or “require security team review for authentication changes” without complex YAML configuration. These rules become more powerful when combined with GitHub Actions integration, which triggers them automatically on specific file patterns or PR events and turns static rules into workflow automation.
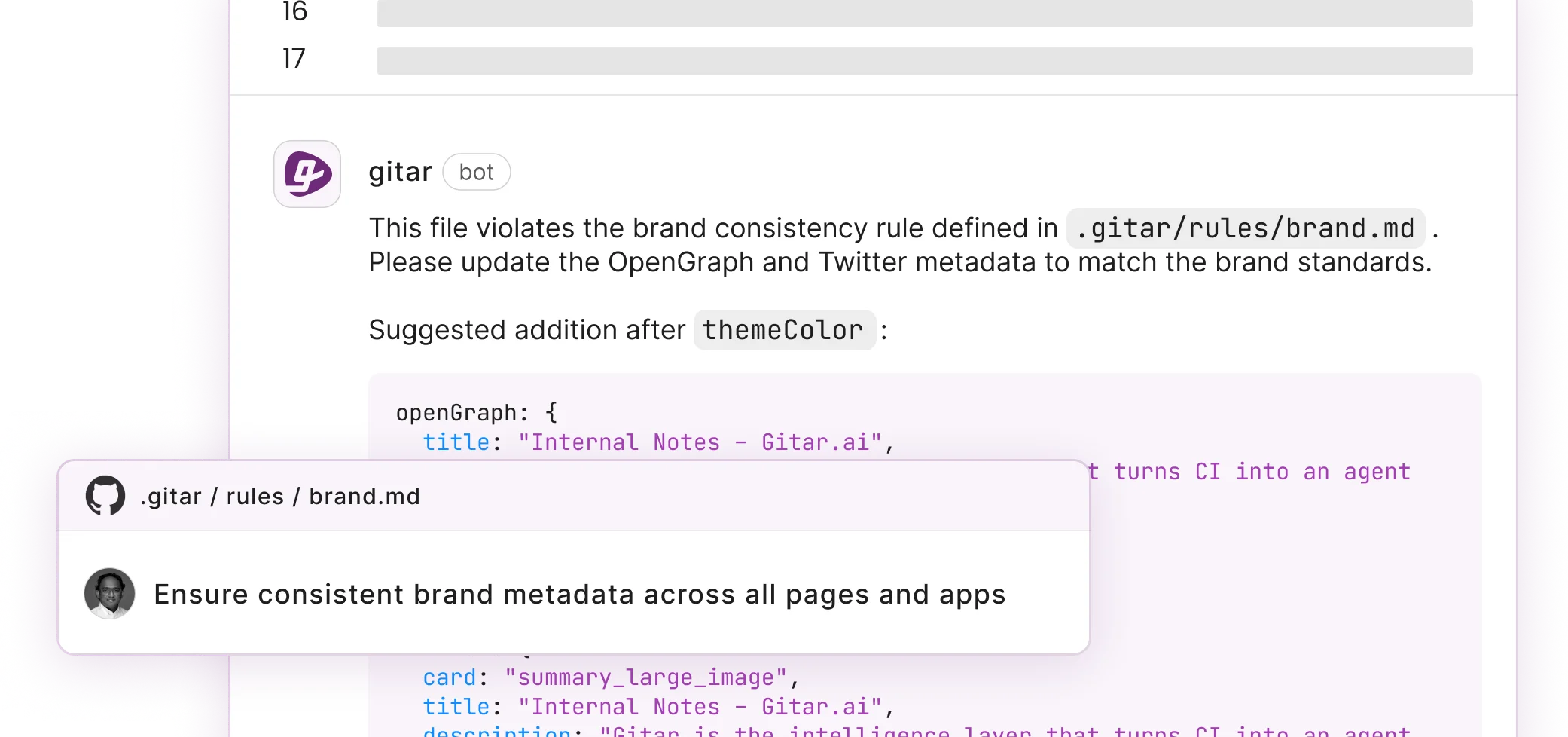
In Practice: Auto-learning from team patterns makes rules more precise over time. As the system understands your codebase’s unique characteristics and coding standards, it reduces false positives and focuses attention on meaningful changes.
4. Severity Thresholds and Smart Prioritization
Well-tuned SAST deployments with custom rules and framework awareness reduce false positives from 30-60% to 10-20%, with below 10% considered excellent, and hybrid LLM-static methods have achieved 94-98% reduction in industrial settings. SonarQube quality gates can block merges on critical findings while ignoring low-severity noise so developers focus on issues that truly matter.
The Gitar Advantage: Gitar collapses resolved findings from previous reviews and surfaces critical bugs at the top. The platform automatically prioritizes signal over noise in a single dashboard comment, which keeps review focus on the highest-impact problems.
Configuration alone cannot handle every edge case. Human feedback needs to flow back into the system so it learns which patterns your team considers noise.
Human-AI Feedback Loops That Keep Tools Accurate
5. Feedback Loops and Suppressions That Learn Over Time
Feedback loops where developers flag false positives with a “not a bug” button route them to security teams for rule tuning, and the top five noisiest rules often account for most false positives. Hybrid LLM-static analysis methods eliminated 94-98% of false positives while maintaining high recall in Tencent’s industrial dataset.
How Gitar Learns: Gitar’s Judge guardrail system collapses duplicate outputs, strips internal references, and drops replies that add nothing. The platform applies reviewer feedback autonomously instead of relying on manual rule updates, which keeps noise low as patterns evolve.
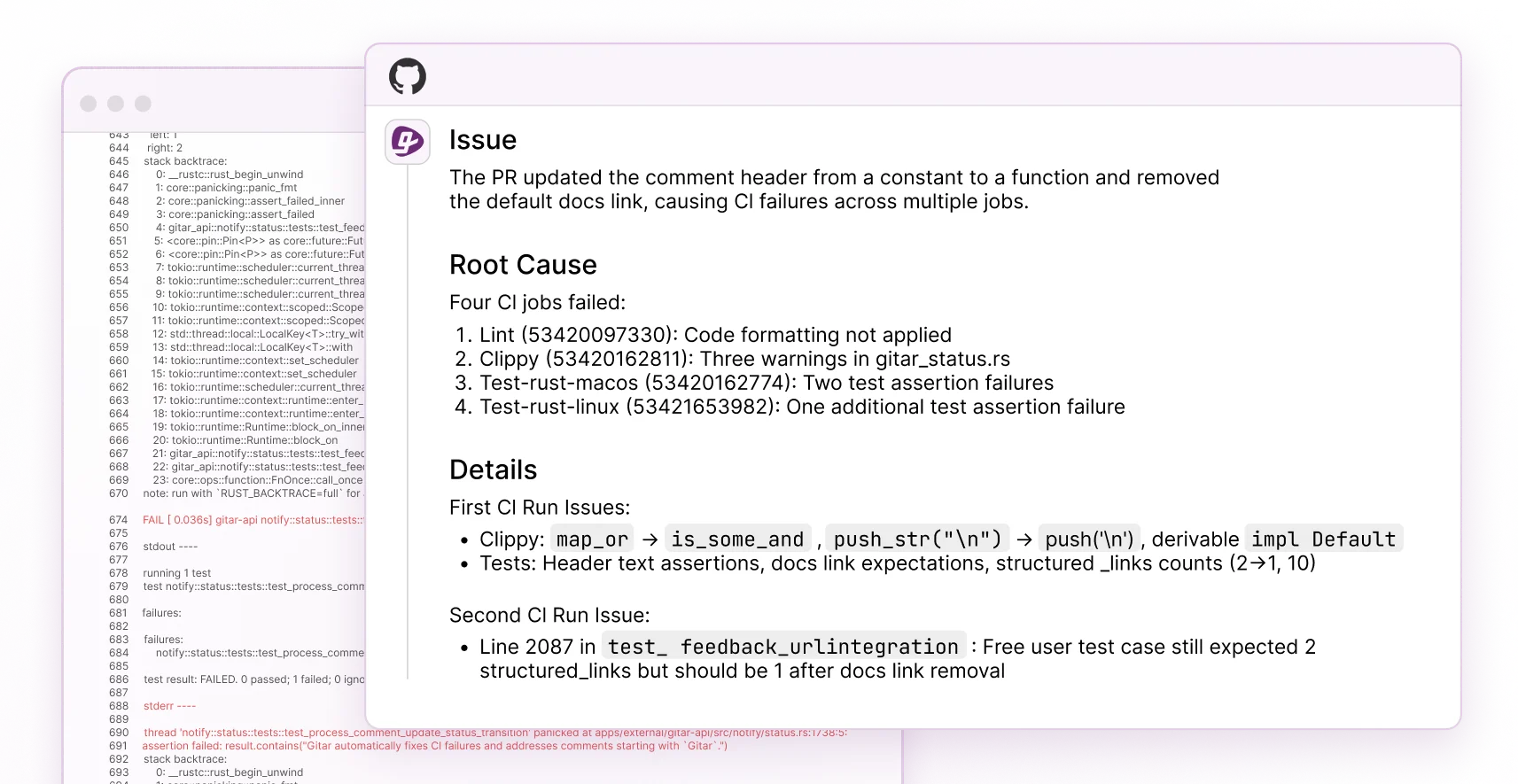
6. Unrelated Failure Detection in CI Pipelines
Teams reduce false positives further by separating infrastructure flakiness from code bugs using CI context that traditional reviewers lack. Without this context, developers spend hours debugging “failures” that actually stem from environment issues or timing problems unrelated to their changes.
Real-World Impact: Collate’s engineering lead highlighted Gitar’s “unrelated PR failure detection” as saving “significant time” by identifying when failures come from infrastructure issues instead of code problems. This capability removes a major source of false positive noise from environmental factors.
7. Tool Selection Focused on Low False Positives
Graphite Agent maintains an unhelpful comment rate under 3% through deep codebase analysis, while Greptile has the highest false positive rate among AI code review tools in independent evaluations. Early AI code review tools caught one real bug for every nine false positives, which led teams to ignore them.
Why Teams Choose Gitar: Gitar provides autonomous validation and real fixes instead of only suggestions. Competing tools often charge $15-30 per developer for comments that still require manual work, while Gitar’s 14-day trial proves ROI through actual fixes.
ROI Summary: Measuring the Impact
Combining all seven tactics creates compounding gains. Contextual AI analysis, framework-aware tuning, custom rules, severity thresholds, feedback loops, unrelated failure detection, and careful tool selection together free developers from noisy CI failures and low-value review work. The table below shows what a 20-developer team can expect after adopting Gitar.
|
Metric |
Before Gitar |
After Gitar |
Annual Savings |
|
CI time per developer |
1 hour/day |
15 minutes/day |
$750K (20-dev team) |
|
Context switching |
Multiple/day |
Near-zero |
Focus on real work |
|
Green build guarantee |
Manual fixes |
Automatic |
Immediate deployment |
Measure the ROI yourself by installing Gitar and tracking your team’s productivity gains within days.
Frequently Asked Questions
How Gitar Reduces AI Code Review False Positives
Gitar uses a multi-layered approach that combines contextual AI analysis, framework-aware tuning, and autonomous validation. The Judge guardrail system filters irrelevant inputs, collapses duplicate outputs, and drops low-value comments before they reach developers. Unlike suggestion-only tools, Gitar validates fixes against your actual CI environment so recommendations work before they appear in the PR. The hierarchical memory system learns your team’s patterns over time and reduces false flags on known coding standards and architectural decisions.
How Gitar Compares to CodeRabbit for False Positives
CodeRabbit achieves 46% bug detection accuracy, so 54% of its findings are noise that developers must manually filter. CodeRabbit leaves suggestions in comments that still require manual implementation and validation. Gitar auto-applies fixes that are validated against CI, which guarantees they work. The single dashboard comment approach removes notification spam, while CodeRabbit scatters inline comments throughout your diff. Teams report Gitar’s summaries are more concise and more actionable than competing tools.
Trial Details for Testing Gitar’s False Positive Reduction
Gitar offers a 14-day free trial of the Team Plan with full access to auto-fix capabilities, custom rules, CI integration, and all platform features. The trial has no seat limits, so your entire team can experience the false positive reduction firsthand. You can measure the impact on sprint velocity, CI failure rates, and developer productivity before making any financial commitment. The trial supports GitHub, GitLab, CircleCI, and Buildkite integrations.
Trusting Gitar’s Automated Commits
Gitar provides configurable automation levels so teams can build trust gradually. You can start in suggestion mode, review and approve every fix, and confirm the quality. After that, you can enable auto-commit for specific failure types such as lint errors or test fixes. The platform validates all fixes against your actual CI environment before applying them, unlike tools that make unverified suggestions. Enterprise deployments can run the agent within your own CI pipeline for maximum security and control.
Working with Complex CI Setups and Custom Frameworks
Complex CI environments are where Gitar performs best. The platform emulates your full environment, including specific SDK versions, multi-dependency builds, and third-party security scans. Framework-aware analysis understands custom sanitization libraries and internal patterns that often trigger false positives in generic tools. The Enterprise tier runs the agent inside your own CI with access to secrets and caches so fixes work in your production environment, not only in isolation.
Conclusion: Turn Down the Noise and Fix Real Problems
The post-AI coding crisis floods development teams with noise from CI failures and review friction, which our ROI analysis shows can reach $750K annually for a 20-developer team. While competitors charge $15-30 per developer for suggestion engines that still require manual work, Gitar’s Healing Engine autonomously validates and applies fixes through contextual analysis and CI integration.
The seven tactics in this guide, from contextual AI analysis to human-AI feedback loops, deliver the strongest results when they operate inside a single platform instead of as disconnected tools. Gitar combines all these approaches in one autonomous system that learns your team’s patterns and keeps builds green.
Get started with Gitar’s Team Plan trial and eliminate false positives while guaranteeing green builds.